Leseprobe
Page 1
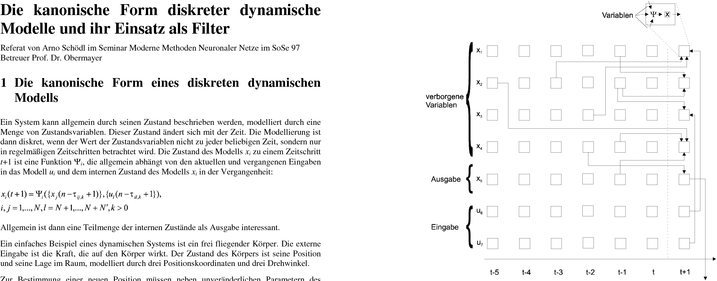
Körpers (Masse, Drehträgheit) die aktuell wirkende Kraft und die Position der letzten beiden
1.1 Die Bestimmung der minimalen Zustandsmenge Zeitschritte bekannt sein. Die letzten beiden Zeitschritte werden benötigt, um die
Geschwindigkeit des Körpers zu bestimmen, die sich gemäß der wirkende Kraft verändert.

Die Daraus wird dann die neue Position und Lage bestimmt.
Zustandsmenge geschieht mithilfe von
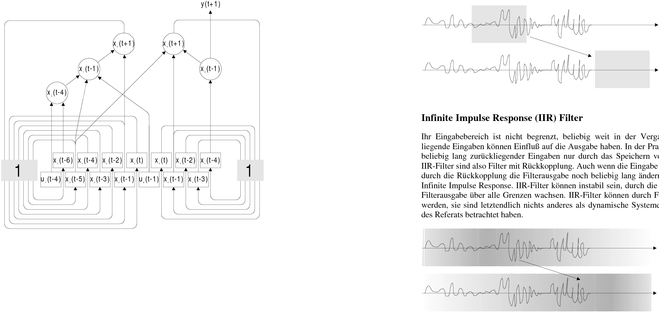
Die Abhängigkeit der Funktion Ψi für jede Zustandsvariable xi von den vergangenen Graphtransformationen. Dazu wird der
Zuständen und den Eingaben kann in einem Graph dargestellt werden, hier anhand eines angegebene Graph 1 in eine andere
Beispielmodells, das wir im nächsten Abschnitt noch weiter betrachten. Mit jedem Zeitschritt Darstellung überführt. Wir fassen alle
wird nach den Funktionen der Zustandsvariablen aus vergangenen Zuständen und externen Knoten eines Zustands zu verschiedenen
Eingaben ein neuer Satz Zustandsvariablen erzeugt (siehe Bild rechts). Zeiten im vorgestellten Graph zu einem
Knoten zusammen. Benötigt nun ein
Möchte man ein solches System implementieren, steht man vor einem Problem: Zur Zustand xi den Wert eines vergangenen
Berechnung eines neuen Zustands werden alte Eingaben und Zustände benötigt, die Zustands xj zur Berechnung, geht also eine Kante in Graph 1 von einer vergangenen Ausgabe gespeichert werden müssen. Man möchte jedoch nur möglichst wenig Zustände für möglichst des Zustands xj zu dem Zustand xi, so wird im neuen Graph 2 auch eine Kante von xj nach xi
kurze Zeitabschnitte speichern. Der erste Teil des Referats beschäftigt sich mit der eingeführt, die die Länge der Verzögerung hat. Die Länge der Kante ist 0, wenn der aktuelle Bestimmung dieses minimalen Zustandsvektors der gespeicherten Variableninhalte. (und schon irgendwie neu berechnete) Wert der Zustandsvariable gebraucht wird. Eine solche
Kante kann man sich als eine Art Warteschlange mit dieser Länge vorstellen, der Wert des Der zweite Teil des Referats beschreibt die Anwendung dieser diskreten dynamischen
Zustands wird dort bei jedem Zeitschritt eingeschoben, je nach Länge fällt am anderen Ende Modelle als adaptive Filter, d. h. solche, die sich während des Filtervorgangs an die zu
der Kante ein vergangener Wert des Zustands heraus. Wichtig ist, daß immer nur der letzte filternden Daten anpassen können. Dazu werden die Zustandsfunktionen des dynamischen
Wert der Warteschlange zur Verfügung steht, Werte in der Mitte der Warteschlange sind Systems als neuronale Netze implementiert und die Netze anhand der zu filternden Daten
unzugänglich. Das Bild rechts oben zeigt diesen Graph für das Beispielmodell. trainiert.
Page 2

nacheinander wiederholt, bis sich der Graph nicht mehr verändert:
Wir wenden die Schritte 2.1-2.3 auf unseren Beispielgraph an. Schritt 2.1 wird hier nicht 2.1 Knoten, deren zuführende Kanten alle den Delay 0 haben,
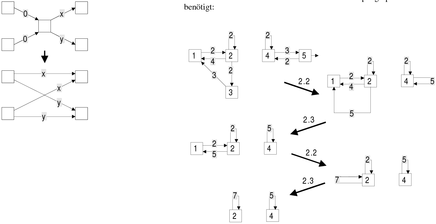
können gelöscht werden. Statt das Ergebnis der Funktion zu
verzögern, können auch alle Eingaben der Funktion um die
gleiche Zeit verzögert werden und die Funktion selbst in den
Knoten, die die Ausgabe der Funktion benötigen, berechnet
werden.
Page 3
Durch die Wahl der Transformationen haben wir sichergestellt, daß wir alle Variablen in den Die folgende Formel rechnet gemäß den vorangegangenen Überlegungen die Anzahl der
Zyklen des Systems mit den nun noch übriggebliebenen gespeicherten Variablen vollständig gespeicherten Variableninhalte aus, die für den ersten Zeitschritt initialisiert und von
Zeitschritt zu Zeitschritt gespeichert werden müssen: berechnen können, wenn wir sie in geeigneten Zeitbereichen speichern, so daß sie
entsprechend den Kanten verzögert zur Berechnung eines neuen Zeitschritts zur Verfügung

stehen. Wichtig ist, daß die Speicherung von Zuständen nur für Zyklen notwendig ist und die
Größe des Zustandsvektors, also die minimale Anzahl der Speicherplätze für Variablen, für
das auf seine Zyklen reduzierte Modell die gleiche ist wie für das vollständige Modell.
Die gespeicherten vergangenen Inhalte von Variablen müssen vor der Berechnung des ersten
Zeitschritts mit irgendwelchen Werten initialisiert werden, da sie ja auch schon für die
Berechnung des ersten Zeitschritts gebraucht werden. Auf dieser Grundlage überlegen wir
nun, wie viele Variableninhalte einer bestimmten Zustandsvariablen in der Vergangenheit
initialisiert werden müssen, um die Berechnung eines Zeitschritts zu ermöglichen. Für unser Beispielmodell ist die Berechnung ziemlich einfach:
Um eine Variable i auszurechnen, müssen ja alle Eingaben der Berechnungsfunktion Ψi max (7 - min (7 - 7), 0) + max (5 - min (5 - 5), 0) = 12
vorliegen. Läuft das System zu einem Zeitpunkt t0 los, kann selbst, wenn die Werte aller
Es müssen also 12 verschiedene Variableninhalte gespeichert werden. Variablen ab diesem Zeitpunkt bekannt sind, ein neuer Wert der Variablen i erst nach Ablauf
des längsten Delays einer Eingabe von Ψi berechnet werden. Alle früheren Inhalte der
Variablen i in der Vergangenheit müssen zunächst vor Systemstart initialisiert werden,
ausgerechnet werden können sie nicht. 1.2 Die Bestimmung des Zustandsvektors
Aber warum sollen wir Variableninhalte initialisieren, nach denen uns nie jemand fragt, mit
Nun ist die Größe des Zustandsvektors bekannt, also die minimale Anzahl der Werte von anderen Worten, die keiner anderen Funktion Ψj einer Variablen j als Eingabe dienen? Die
Variablen, die gespeichert werden müssen, um das Modell ablaufen zu lassen. Welche Variable j wird ebenso wie die Variabel i erst ab dem Zeitpunkt berechnet, ab dem die
konkreten Variablen jedoch zu welchen konkreten Zeitabschnitten gespeichert werden Eingabe mit dem längsten Delay von Ψj zur Verfügung steht. Ist der Delay der Variablen i,
müssen, hängt auch von den Zusammenhängen zwischen den Zyklen ab. Zur Beantwortung die Ψj als Eingabe erhält, nun kürzer als der maximale Delay einer Eingabe von Ψj , benötigt
wird der Graph des Modells deshalb ganz ähnlich vereinfacht, wie bereits oben gezeigt, nur zumindest Ψj die ältesten Werte der Variablen i nicht. Gilt das für alle Funktionen Ψx, die die
müssen Beziehungen zwischen den Zyklen erhalten bleiben, weil ja Variableninhalte eines Variable i als Eingabe haben, müssen diese ältesten Inhalte nicht initialisiert und eben auch Zyklus für einen anderen Zyklus als Eingabe dienen können und zu diesem Zweck erhalten nicht gespeichert werden. Das folgende Bild veranschaulicht noch einmal den Sachverhalt: werden müssen.
Page 4
oder äquivalent
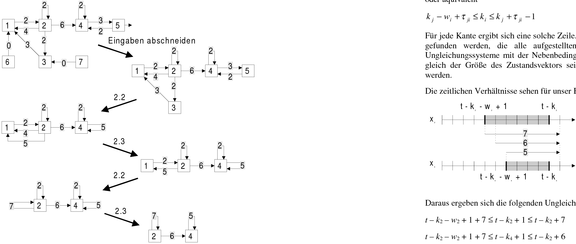
t - k4 - w4 + 1 + 7 ≤ t - k4 + 1 ≤ t - k4 + 7
Zustandsvariablen, die gespeichert werden müssen, befinden sich nur in Zyklen. Alle Knoten,
Außerdem muß gelten:
die außerhalb von Zyklen liegen, werden daher im letzten Schritt mitsamt ankommenden und
abgehenden Kanten gelöscht. Kanten, die Zyklen miteinander verbinden, bleiben so erhalten. w2 + w4 = 12
Die übriggebliebenen Knoten sind die Zustandsvariablen des Systems und die Kanten zeigen Ein möglicher Zustandsvektor unseres Systems ist demnach:
die notwendigen Verzögerungen der Werte dieser Zustandsvariablen bei der Berechnung
{ x2(t), x2(t-1), ..., x2(t-6), x4(t), x4(t-1), ..., x4(t-4) } eines neuen Zeitschritts an.
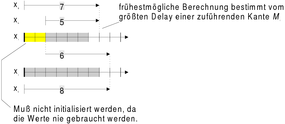
Von jeder Variablen i wird nun eine bestimmte Warteschlange gespeichert. Es muß das Alter
des ersten Werts der Warteschlange ki bestimmt werden. Ist ki = 0, steht bei der
1.3 Die kanonische Form Neuberechnung des nächsten Zeitschritts t+1 der Wert der Variable i zum Zeitpunkt t zur
Verfügung und ihr Wert für t+1 wird in diesem Zeitschritt berechnet. Ist ki>0, hängt die
Ist der Zustandsvektor bekannt, kann nun die kanonische Form des Netzes erzeugt werden. In Berechnung der Variablen i entsprechend viele Zeitschritte hinterher.
jedem Zeitschritt müssen die Werte des Zustandsvektors aktualisiert werden. Ebenso wie das
Der Parameter wi ist dagegen einfach die Länge der Warteschlange. Haben wir die Größe des Bestimmen von etwaigen Ausgabevariablen, die nicht im Zustandsvektor enthalten sind,
Zustandsvektors v nach Abschnitt 1.1 schon bestimmt, muß nun natürlich gelten erfolgt das Bestimmen der neuen Werte des Zustandsvektors durch Berechnen der
Bildungsfunktion Ψ der jeweiligen Variable. Jede Funktion Ψ benötigt bestimmte Variablen ∑ w i = v mit bestimmten Verzögerungen als Eingaben. Sind diese Variablen mit den gewünschten
Verzögerungen nicht direkt im Zustandsvektor enthalten, so werden diese Variablen Geht nun im Graph eine Kante von Variable i nach Variable j mit der Verzögerung τ ji, muß wiederum berechnet gemäß ihrer Funktion Ψ und die Eingaben dieser Funktion werden
bei Neuberechnung der Variable j zu jedem neuen Zeitschritt t+1, wenn der Werte der wiederum dem Zustandsvektor entnommen oder berechnet, solange, bis alle Eingaben der
Variablen zur Zeit t+1-kj bestimmt werden soll, der Wert der Variablen i mit der Funktion im Zustandsvektor enthalten sind. Die korrekte Wahl des Zustandsvektors stellt
entsprechenden zusätzlichen Verzögerung in der Warteschlange stehen. Also muß gelten: sicher, daß das irgendwann der Fall ist. Viele Variablen müssen dabei nur einmal berechnet
werden und werden von mehreren Funktionen als Eingabe gebraucht. Trotzdem kann der τ τ + − ≤ + − ≤ + + − − k n k t w k t 1 1 ji i j ji i i Rechenmehraufwand im Vergleich zu einer naiven Implementierung mit einem größeren
Page 5
Zustandsvektor erheblich sein. Eingabevariablen stehen dabei, wie weiter oben schon gesagt, 2 Der Einsatz neuronaler Netze als Filter
vereinbarungsgemäß zu jedem beliebigen Zeitpunkt zur Verfügung.
Jede Funktion zur Berechnung einer Variablen kann dabei innerhalb der kanonischen Form Filter arbeiten auf einer zeitlich geordneten Folge von Eingaben, dem Eingabestrom, und
mehrfach vorkommen zur Berechnung der Variablen zu unterschiedlichen Zeitpunkten. Wird liefern eine ebenso zeitlich geordnete Folge von Ausgaben. Man unterscheidet grundsätzlich
die Funktion dabei von einem neuronalen Feedforward-Netz repräsentiert, muß dieses Netz zwei verschiedene Arten von Filtern.
zum Beispiel für das Training per Backpropagation mehrfach vorhanden sein. Allerdings ist
die repräsentierte Funktion jedesmal die gleiche, die Gewichte des Netzes sollten also in allen
seinen Instanzen übereinstimmen. Man spricht dabei von Shared Weights, die Gewichte des Finite Impulse Response (FIR) Filter
Netzes, das die entsprechende Funktion berechnet, kommen eben mehrfach vor, müssen aber
durch entsprechende Updategesetze beim Training des Netzes gleich gehalten werden, weil Diese Filter haben als Eingabe einen zeitlich beschränkten Ausschnitt aus dem Eingabestrom
sie ja die gleiche Funktion berechnen sollen. und keine Rückkopplung, speichern also keine Zustände. Ihre Ausgabe hängt nur von dem
diesem Ausschnitt aus dem Eingabestrom ab, weiter in der Vergangenheit liegende Eingaben
Das hier vorgestellte Verfahren zur Bestimmung der kanonischen Form eines diskreten haben keinen Einfluß auf die Filterausgabe. Der Name Finite Impulse Response rührt daher,
dynamischen Modells ist nicht nur vollständig automatisierbar, sondern auch noch daß, wenn die Eingabe verschwindet, also Null wird, nach endlicher Zeit auch die Ausgabe
polynomiell in Rechenzeit und Speicherplatz.
verschwindet oder zumindest konstant wird. Die Antwort auf einen Impuls der Eingabe ist
also endlich. Ein FIR-Filter ist immer stabil in dem Sinne, daß bei endlicher Eingabe keine Zum Schluß noch die kanonische Form unseres Beispielmodells, es kommen keine Shared
über alle Grenzen wachsende Ausgabe auftreten kann, eine überall endliche Filterfunktion Weights vor:
vorausgesetzt. FIR-Filter können durch Feedforward-Netze realisiert werden.
Page 6
Man kann sich auch darauf beschränken, nicht jeden, sondern nur alle n Zeitschritte eine 2.1 Adaptiver FIR-Filter mit Feedforward-Netz
Trainingsphase einzulegen und dazwischen das Netz unverändert als Filter arbeiten zu lassen.
Das spart Rechenzeit, und es sind nicht für alle Zeitschritte Zielausgaben erforderlich. Ein einzelner Zeitschritt: Wir wollen nun den Einsatz
neuronaler Netze als adaptive Filter
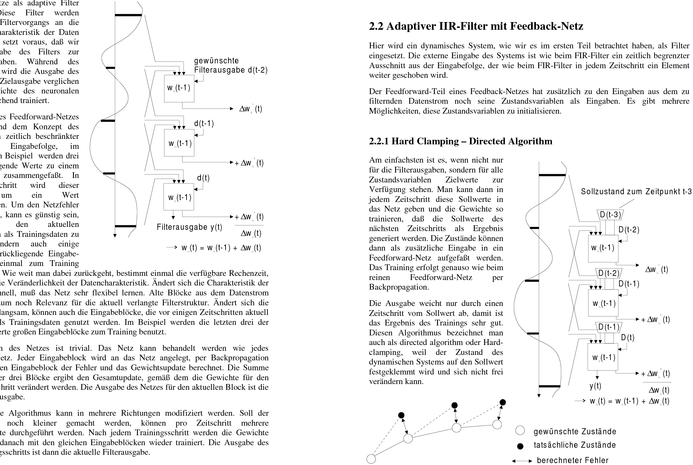
betrachten. Diese Filter werden
während des Filtervorgangs an die
wechselnde Charakteristik der Daten
angepaßt. Das setzt voraus, daß wir
eine Zielausgabe des Filters zur
Verfügung haben. Während des
Filtervorgangs wird die Ausgabe des
Filters mit der Zielausgabe verglichen
und die Gewichte des neuronalen
Netzes entsprechend trainiert.
Die Eingabe des Feedforward-Netzes
ist entsprechend dem Konzept des
FIR-Filters ein zeitlich beschränkter
Bereich der Eingabefolge, im
nebenstehenden Beispiel werden drei
aufeinanderfolgende Werte zu einem
Eingabeblock zusammengefaßt. In
jedem Zeitschritt
Abschnitt
weitergeschoben. Um den Netzfehler
klein zu halten, kann es günstig sein,
nicht nur
Eingabebereich als Trainingsdaten zu
benutzen, sondern auch einige
Zeitschritte zurückliegende Eingabe-blöcke noch einmal zum Training
heranzuziehen. Wie weit man dabei zurückgeht, bestimmt einmal die verfügbare Rechenzeit,
zum anderen die Veränderlichkeit der Datencharakteristik. Ändert sich die Charakteristik der
Daten sehr schnell, muß das Netz sehr flexibel lernen. Alte Blöcke aus dem Datenstrom
haben dann kaum noch Relevanz für die aktuell verlangte Filterstruktur. Ändert sich die
Charakteristik langsam, können auch die Eingabeblöcke, die vor einigen Zeitschritten aktuell
waren, noch als Trainingsdaten genutzt werden. Im Beispiel werden die letzten drei der
jeweils drei Werte großen Eingabeblöcke zum Training benutzt.
Das Trainieren des Netzes ist trivial. Das Netz kann behandelt werden wie jedes
Feedforward-Netz. Jeder Eingabeblock wird an das Netz angelegt, per Backpropagation
werden für jeden Eingabeblock der Fehler und das Gewichtsupdate berechnet. Die Summe
der Updates der drei Blöcke ergibt den Gesamtupdate, gemäß dem die Gewichte für den
nächsten Zeitschritt verändert werden. Die Ausgabe des Netzes für den aktuellen Block ist die
aktuelle Filterausgabe.
Dieser einfache Algorithmus kann in mehrere Richtungen modifiziert werden. Soll der
Ausgabefehler noch kleiner gemacht werden, können pro Zeitschritt mehrere
Trainingsschritte durchgeführt werden. Nach jedem Trainingsschritt werden die Gewichte
verändert und danach mit den gleichen Eingabeblöcken wieder trainiert. Die Ausgabe des
letzten Trainingsschritts ist dann die aktuelle Filterausgabe.
Page 7
2.2.2 Semidirected Algorithm 2.2.3 Undirected Algorithm
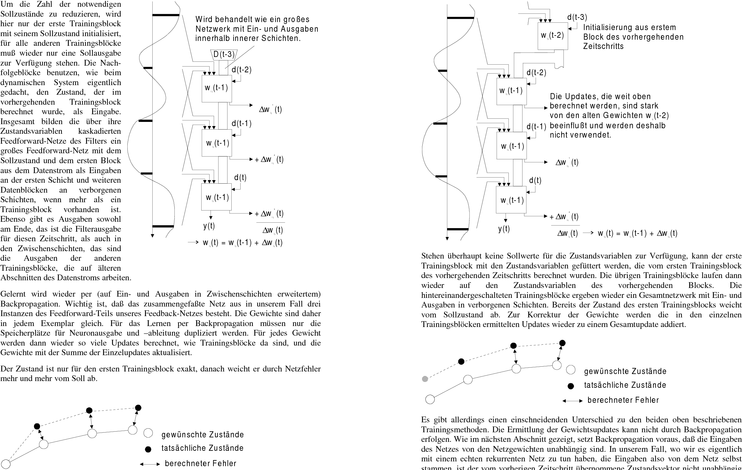
von den Gewichten. Diese Abhängigkeit sollte berücksichtigt werden, indem zu jeder
Page 8
Das ist die Ausgabe eines Neurons: Zustandsvariablen die Abhängigkeit bezüglich der Gewichte in Form eines Gradienten mit
übergeben werden. Die Berechnung des Netzfehlers durch Forward Computation erlaubt
![]()
diese Berücksichtigung.
Die Berücksichtigung des Gradienten des vom vorhergehenden Zeitschritt übernommenen
Zustands macht die Berechnung zwar genauer, jedoch auch nicht exakt, weil sich der vom
![]()
wobei vorhergehenden Zeitschritt übernommene Gradient auf die Werte der Gewichte dieses
Zeitschritts bezieht, nicht auf die aktuellen Gewichte, die bereits durch das Gewichtsupdate
korrigiert wurden. Ein gewisser Fehler bei der Berechnung des Gewichtsupdates kann daher
nicht vermieden werden. Eine Möglichkeit, den Fehler klein zu halten, ist, die errechneten
Die einfach ausgerechnete Ableitung der Ausgabe ist: Updates der ersten Trainingsblöcke nicht in das Gesamtupdate einzubeziehen, da sie noch zu
stark von den alten Gewichten beeinflußt sind. Im Beispiel wurde das Update des ersten
![]()
Trainingsblocks verworfen.
Natürlich kann Backpropagation trotz allem benutzt werden, es ist erheblich schneller als
Forward Computation, nur ist das Gewichtsupdate dann entsprechend stärker fehlerbehaftet. Wie man sieht, werden die Ableitungen der Neuroneingabe für die Berechnung der Ableitung
der Ausgabe benötigt. Wieviele Summanden müssen verarbeitet werden? Für jeden Eingang
eines Neurons steht ein Term in den Summen. Im ganzen Netz stehen so viele Terme in den
Summen, wie es Eingänge in Neurone und damit Gewichte im Netz gibt. Die Komplexität der 2.3 Methoden zur Berechnung des Fehlergradienten
Berechnung der oben genannten Formel ist daher O(n), wenn n die Anzahl der Gewichte ist.
Wichtig ist, daß die oben genannte Formel für jedes (!) Gewicht ausgerechnet werden muß,
denn sie bezeichnet nur die Ableitung nach einem Gewicht, es wird aber die Ableitung nach
2.3.1 Forward Computation
jedem Gewicht benötigt, zusammen bilden die Ableitungen dann wieder den Gradientvektor
des Neuronausgangs. Also muß die Formel für nicht nur einmal, sondern n mal für jedes
Forward Computation ist die intuitivere der beiden Methoden zur Berechnung des Netzfehlers Neuron angewandt werden. Die Komplexität der Forward Computation ist daher O(n 2 ).
und seines Gradienten. Jedes Eingabeneuron bringt zusätzlich zu seiner Aktivität noch die
Ableitungen der Aktivität nach allen Gewichten als ein Gradientvektor in das Netz. Ist die Der Vorteil diese langsamen Verfahrens ist, daß ein Gradient der Eingabe leicht
Eingabe unabhängig von den Gewichten, das ist normalerweise der Fall, sind diese berücksichtigt werden kann.
Ableitungen eben alle Null.
Nun berechnet jedes Neuron aus der Ableitung seiner Eingänge nach den Gewichten die 2.3.2 Backpropagation
Ableitung seines Ausgangs nach den Gewichten. So wird von den Eingängen zum
Netzausgang die Ableitung der Gewichte zusammen mit der Netzausgabe durch das Netz Wir sind eigentlich ja nicht an der Ableitung irgendwelcher Neuronausgaben interessiert,
propagiert. Am Ende erfolgt dann die Berechnung der Ableitung des Netzfehlers, die hier sondern nur an der Ableitung des Fehlers nach den Gewichten, am Ende sollen schließlich
nicht angegeben, weil trivial ist.
Gewichtsupdates bestimmt werden, die den Fehler minimieren. Nun stellen wir folgende
Schlüsselbeobachtung an: Ändere ich ein Gewicht wij, ändert sich dadurch für das Netz nur

Page 9

Die noch fehlende Ableitung der kumulierten Netzeingabe nach dem Gewicht an der
zuführende Kante ist einfach die Ausgabe des Neurons, das über diese Kante feuert.

j
bewirkten Änderung der Eingabe des damit verbundenen Neurons berücksichtigt wird. Ein
die kumulierte Eingabe des Neurons i ist. Gradient der Eingaben kann daher nicht berücksichtigt werden.
Die Ausgabe des Neurons i verändert den Netzfehler durch die Veränderung der kumulierten Backpropagation ist schnell: Es gibt im ganzen Netz wieder soviel Terme der Summe, wie es
Neuroneingabe der nachgeschalteten Neurone k, die Summe über alle nachgeschalteten Kanten bzw. Gewichte gibt, aber für jedes Neuron wird die Formel nur einmal ausgewertet.
Neurone k ergibt die Gesamtänderung: Die Komplexität von Backpropagation ist daher O(n), wenn n die Anzahl der Gewichte ist.
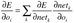
Der Trade-off zwischen Forward Computation und Backpropagation wird jetzt deutlich: Bei
Backpropagation kann sich die Veränderung eines Gewichts nur an einer der n Kanten
auswirken. Bei der Forward Computation kann theoretisch jedes Gewicht den Gradienten an
Insgesamt ergibt sich jeder Kante verändern, es ist nicht zwingend, daß jedes Gewicht nur an seiner Kante wirkt,
wie es in der Praxis neuronaler Netze geschieht. Die Reduktion von n möglichen Kanten zu

der einen, der das Gewicht wirklich zugeordnet ist, ergibt die Komplexitätsverbesserung um
den Faktor n, gleichzeitig aber die genannte Einschränkung, daß Gradienten irgendwelcher
Eingaben nicht berücksichtigt werden können.

O. Nerrand et al., Neural Networks and Nonlinear Adaptive Filtering: Unifying Concepts and
In einem Backpropagationsschritt wird für jedes Neuron zunächst der verteilte Fehler
berechnet:
![]()
wobei -δk der verteilte Fehler des Neurons k ist.
Wie man sieht, wird dazu der verteilte Fehler der nachgeschalteten Neuronen gebraucht, der
im vorhergehenden Schritt berechnet wurde und nun zurückpropagiert wird. Die Ableitung
der kumulierten Netzeingabe des Neurons k nach der Ausgabe des Neurons i, das seine
Ausgabe an Neuron k schickt, ist einfach das Gewicht zwischen beiden Neuronen. Die
Ableitung der Ausgabe von Neuron i nach seiner kumulierten Eingabe ist die Ableitung der
Squashing function.
- Arbeit zitieren
- Arno Schödl (Autor:in), 1997, Die kanonische Form diskreter dynamischer Modelle und ihr Einsatz als Filter, München, GRIN Verlag, https://www.grin.com/document/96308

Ähnliche Arbeiten


















Kostenlos Autor werden


Kommentare