Leseprobe
Kapitel 1 Einführung
1.1 Motivation
Die natürliche Evolution hat sich zur Erzeugung und Anpassung von Lebewesen an eine sich ändernde Umgebung als höchst erfolgreicher Mechanismus herausgestellt. Ohne bestimmte Anweisungen oder auch nur genaue Zieldefinitionen zu erhalten, ist es ihr gelungen, raffinierte Lösungen für Probleme der realen Welt zu finden.
Ein Ansatz, die in der natürlichen Evolution steckende kreative Kraft zur automatischen Entwicklung von Computer-Programmen zu verwenden, ist die Genetische Programmierung (GP) (vgl. (Koz92, Kapitel 1-6)). Mit ihr wird versucht, Mechanismen der natürlichen Evolution nachzuahmen, um automatisch Programme zu erzeugen, die ein gegebenes Problem lösen. GP ist in einer Reihe von Anwendungen sowohl zum Lösen mathematischer Probleme als auch zum Beheben von Problemen der realen Welt erfolgreich angewandt worden. Hierzu zählen z.B. Symbolische Regression (Koz92, S. Kapitel 10), Klassifikation (Koz92, Kapitel 17), Synthese Künstlicher Neuronaler Netze (Gru94, Kapitel 2f), Muster Erkennung (Tac93, S. 2-10), Roboter Steuerung (BNO97, S. 2-10) und Generierung von Bildern (GH97, S. 2-7).
Das maschinelle Lernen mittels GP kann als ein heuristischer Suchalgorithmus interpretiert werden, der in der Menge aller möglichen Programme diejenigen sucht, die das gegebene Problem am besten lösen. Da der Suchraum je nach gegebenem Problem sehr groß und oft weder stetig noch differenzierbar ist, eignet sich der Suchraum aller möglichen Programme schlecht für klassische Suchalgorithmen (vgl. (LP02, S. 2f)).
Das Anwendungsgebiet der GP in dieser Arbeit ist die Erzeugung von Handelssystemen für den Finanzmarkt, insbesondere für den Währungsmarkt. An den Finanzmärkten handeln erfolgreiche spekulative Händler gewöhnlich aufgrund gewisser Regelwerke. Diese Regelwerke sind jedoch relativ starker individueller interpretation unterworfen. Bei genauer Betrachtung fällt auf, dass Händler die Regeln, nach denen sie zu handeln meinen, in entscheidenden Situationen beugen und gewissermaßen nach ihrem „Bauchgefühl" handeln. Evtl. unterscheidet dieser Anteil an intuitivem Handeln einen erfahrenen profitablen Händler von einem unerfahrenen unprofitablen Händler, auch wenn beide meinen, nach dem gleichen Regelwerk zu arbeiten. Das Definieren eines Handelssystems durch einen Menschen ist mit Schwierigkeiten verbunden, da er nicht alle Regeln eindeutig wiedergeben kann. Daher hat sich die Übertragung von Regelwerken zum Handeln auf einen Rechner als nicht erfolgreich herausgestellt.
Ein anderer Ansatz ist, den Rechner die Handelsregeln selbst lernen zu lassen. Hierzu werden z.B. Künstliche Neuronale Netze (KNN) erfolgreich eingesetzt (vgl. (Ska01, S. 2-5), (MK, S. 2-7)). Es ist jedoch nicht ohne weiteres möglich, die einzelnen Regeln in einfach deutbarer Weise aus dem Netz zu extrahieren. Diese „Black-Box" Eigenschaft von KNN wird von Anwendern kritisiert.
GP bietet sich als Alternative zu KNN an, da sie direkt Regeln erzeugen kann und sich diese trotz einiger Komplexität besser deuten lassen (vgl. (YCK05, S. S. 23f)). Was die Fähigkeit zur Lösung schwieriger Probleme angeht, sind beide Ansätze vergleichbar (vgl. (BB98, S. 13)).
1.2 Ziel und Aufbau
Ziel dieser Arbeit ist es, GP anzuwenden, um Handelssysteme zu erzeugen und auf Profitabilität im Rahmen einer historischen Simulation zu untersuchen. Ein Softwaresystem, das diese Aufgabe löst, wird entworfen und interessante Implementierungsaspekte dargestellt.
Um Handelssysteme mit GP entwickeln zu können, muss die zu entwickelnde Software einer Reihe von Anforderungen genügen. Die Entwicklung der Handelssysteme soll basierend auf historischen Kurszeitreihen vorgenommen werden. Es wird angenommen, dass sich der Markt mit der Zeit ändert und daher ehemals profitable Handelssysteme an Profitabilität verlieren. Daher ist es nötig, das Entwicklungssystem der Handelssysteme so zu konzipieren, dass im Laufe der Zeit neue, an die geänderten Marktbedingungen angepasste Handelssysteme erzeugt werden können. Um die Versorgung mit aktuellen Kursdaten sicherzustellen, müssen die relevanten Marktdaten kontinuierlich erfasst und dem Entwicklungssystem zur Verfügung gestellt werden. Die Entwicklung profitabler Handelssysteme wird unterstützt, indem Vorverarbeitungen der Kursdaten, die bei Wertpapierhändlern verbreitet sind, dem System zur Verfügung gestellt werden. Zur visuellen Überprüfung sollen die Kursdaten, die Vorverarbeitungen sowie die Transaktionen der Handelssysteme grafisch dargestellt werden. Überoptimierung bei der Entwicklung der Handelssysteme soll verhindert werden, indem die vorhandene Kurshistorie in Trainings-, Validierung- und Testzeitraum unterteilt wird. Um ein Handelssystem für den Testzeitraum zu erhalten, werden die besten Handelssysteme des Trainingszeitraums auf den Validierungszeitraum angewandt. Das beste Handelssystem während der Validierung wird für den Handel im Testzeitraum ausgewählt. Der Entwicklungsprozess soll reproduzierbar und durch Log-Dateien der Zwischenergebnisse transparent sein. Handelssysteme zu großer Komplexität erwecken bei Anwendern Mißtrauen, da sich die Entscheidungen des Systems schwer nachvollziehen lassen. Auch wenn sich mit komplexeren Handelssystemen eine höhere Rendite erzielen ließe, ist eine gewisse Nachvollziehbarkeit der Handelssysteme erstrebenswert. Zusätzlich zur Begrenzung der Größe der Handelssysteme wird die Standard-GP mittels sog. Knotengewichte erweitert. Dadurch wird versucht, einerseits die Makromutation durch den Crossover-Operator zu verringern und andererseits die Interpretierbarkeit der generierten Handelssysteme zu vereinfachen (vgl. Kapitel 3.3.1 auf Seite 43).
Aufbau der Arbeit Zunächst werden in Kapitel 2.1 auf Seite 5 die Grundlagen und der Stand der Technik der Genetischen Programmierung und der Künstlichen Neutronalen Netze dargestellt. Aufbau und Arbeitsweise von KNN wird betrachtet, da dieser Ansatz im Kontext der Entwicklung von Handelssystemen stark verbreitet ist. Im Anschluss daran werden ab Kapitel 2.3 auf Seite 20 die Grundlagen von technischen Handelssystemen dargestellt. Es wird einerseits die Technische Analyse als Instrument zum Finden von günstigen Handelszeitpunkten dargestellt, andererseits ein Ansatz zur Bestimmung der optimalen Positionsgröße für einen Handel aufgezeigt.
Über beide vorgestellte Ansätze des maschinellen Lernens sind im Anwendungsgebiet von verschiedenen Autoren Erfolge berichtet worden. Einige dieser erfolgreichen Anwendungen werden in Kapitel 2.3.7 auf Seite 35 beschrieben.
Ab Kapitel 3 auf Seite 39 wird der Entwurf eines Systems beschrieben, das mittels GP Handelssysteme generiert, optimiert und mit historischen Kursdaten testet. Nach einem Überblick über das System werden die Anforderungen präzisiert dargestellt und ein Konzept für die Software entwickelt. Die Eigenschaften des für die Genetische Programmierung zuständigen Evolutionären Algorithmus werden definiert. Die Implementierungsdetails der Komponenten der entwickelten Software sind ab Kapitel 4 auf Seite 49 dargestellt. Die Resultate der Experimente mit dem System sind ab Kapitel 5 auf Seite 57 aufgeführt.
Anschließend findet eine Diskussion und Bewertung der Ergebnisse sowie ein Ausblick auf mögliche zukünftige Weiterentwicklungen des Systems in Kapitel 6 auf Seite 77 statt. Die Arbeit schließt mit einer Zusammenfassung in Kapitel 7 auf Seite 81
2 Grundlagen und Stand der Technik
In diesem Kapitel werden die Grundlagen Evolutionärer Algorithmen und Künstlicher Neuronaler Netze dargestellt und auf den aktuellen Stand der Technik eingegangen. Anschließend werden die relevanten Grundlagen des Anwendungsgebietes, der technischen Handelssysteme, besprochen.
2.1 Genetische Programmierung
Bei der Genetischen Programmierung (GP) handelt es sich um einen Algorithmus aus der Familie der Evolutionären Algorithmen. In der Natur hat sich die Evolution als sehr erfolgreiches System zur Weiterentwicklung und Optimierung aller Lebewesen erwiesen. Evolutionäre Algorithmen bilden mittels einfacher Modelle die wesentlichen erfolgreichen Merkmale des natürlichen evolutionären Prozesses nach. Sie ermöglichen dadurch, auch bei Problemen mit großem Suchraum mit relativ geringem Aufwand gute Lösungen zu finden. Datenstrukturen und Algorithmen werden durch die Evolutionären Algorithmen erzeugt und optimiert, um gegebene Probleme zu lösen. Diese Einführung in die GP orientiert sich an Banzhaf et al. (BNKF98, Kapitel 1-8) sowie Koza, der in (Koz92) GP erstmalig beschrieben hat.
Im Folgenden wird kurz dargestellt, wie ein Programm in der GP aufgebaut ist und wie die Evolution funktioniert. Anschließend wird auf bestehende Probleme des Verfahrens sowie deren Lösungsansätze eingegangen.
2.1.1 Aufbau eines Programms
Die Individuen, die während der GP evolutionär entwickelt werden, sind Programme. Diese Programme sind aus Funktionen und Terminalen aufgebaut (vgl. (BNKF98, S. 109-118)).
Die Wahl der verwendeten Funktionen innerhalb eines genetischen Programms hängt vom jeweiligen Anwendungsgebiet ab. Eine wesentliche Anforderung an die Auswahl der Funktionen, die dem genetischen Programm zur Verfügung gestellt werden, ist, dass sich aus ihnen eine Lösung für das Anwendungsproblem zusammensetzen lässt. Um den Suchraum nicht unnötig zu vergrößern, sollten jedoch nicht zu viele Funktionen zur Verfügung gestellt werden. Wie auch Banzhaf et al. in (BNKF98, S. 111f) bemerken, ist es nicht sinnvoll, gleich zu Beginn einer Anwendung exakt auf das gegebene Problem zugeschnittene Funktionen zu entwickeln. Da GP sehr kreativ in der Kombination von Funktionen ist, kann es bereits ausreichend sein, einfache Funktionen wie die Boolschen und Arithmetischen Funktionen zur Verfügung zu stellen, um erstaunliche Resultate zu erzielen.
Die Argumente der verwendeten Funktionen sind die Terminale. Sie bestehen zum einen aus den Eingabedaten, mit deren Hilfe das System trainiert, zum anderen aus Konstanten, die im Laufe der Evolution verändert werden. Diese Konstanten nennt man „ephemeral random constants" (ERC) (vgl. (Koz92, S. 242f)).
Die Abgeschlossenenheit der Funktionen bezüglich der Terminale ist wesentliche Voraussetzung für das fehlerfreie Ablaufen der erzeugten Programme. Die verwendeten Funktionen müssen so entworfen sein, dass sie mit allen möglichen Eingabewerten zurechtkommen, z.B wird häufig die Division angepasst, damit das Programm nicht bei Divisionen durch Null beendet wird. Damit festgelegt ist, in welcher Reihenfolge die Funktionen eines Programms ausgewertet werden, werden die Funktionen und Terminale eines Programms in einer entsprechenden Datenstruktur gespeichert. Am häufigsten werden hierzu Bäume verwendet. Aber auch lineare Strukturen sowie allgemeine Graphen werden als Organisationsform verwendet.
Im Fall von Bäumen ist die übliche Reihenfolge der Evaluation von links nach rechts: Es wird der am weitesten links im Baum stehende Knoten ausgeführt, für den alle Eingaben zur Verfügung stehen.
Der prominenteste Vertreter einer linearen Strukturierung der Funktionen und Terminale ist die Simulation einer Registermaschine. Sie verfügt über mehrere Register, einen linearen Speicher für Zuweisungen von Terminalen an die Register sowie Funktionen, welche die Register für Ein-/Ausgabe verwenden. Eine relativ neue Variante der Strukturierung sind gerichtete Graphen, die Zyklen enthalten dürfen (vgl. (BNKF98, S. 116f)). Interessant an dieser Struktur ist, dass sich Schleifen und Rekursion im Laufe der Evolution ergeben und nicht erst durch spezielle Funktionen zur Verfügung gestellt werden müssen. Problematisch könnten überflüssige Zyklen werden, die den Programmablauf unnötig verlängern.
2.1.2 Initialisierung der GP Population
Da der Baum als Datenstruktur für die Individuen am weitesten verbreitet ist und auch für das Anwendungsbeispiel verwendet wird, wird im Folgenden nur diese Datenstruktur berücksichtigt.
Die von Koza in (Koz92, S. 91-94) eingeführten Methoden zur Initialisierung der einzelnen Individuen der Population werden als „Full" bzw. „Growth" bezeichnet. Für die gesamte Population ist die maximale Größe eines einzelnen Programms durch die maximale Tiefe der einzelnen Bäume festgelegt. Im Falle der „Full" Methode zur Initialisierung eines Individuums wird ein Baum maximaler Tiefe angelegt, bei dem alle Knoten zufällig aus der Menge der Funktionen gewählt werden bis auf die Knoten maximaler Tiefe, die zufällig aus der Menge der Terminale gewählt werden. Bei der Methode „Growth" wird der Baum von der Wurzel her aufgebaut, wobei für jeden Knoten zufällig ein Element aus Funktion bzw. Terminal ausgewählt wird. Wird ein Terminal gewählt, ist der Aufbau für diesen Ast beendet und es wird beim letzten Knoten des Astes fortgefahren, der kein Terminal ist. Für die Knoten der maximalen Tiefe des Baumes wird die zufällige Auswahl auf die Menge der Terminale eingeschränkt.
Um eine möglichst hohe Vielfalt innerhalb der Population zu erreichen, werden die beiden beschriebenen Aufbauverfahren häufig kombiniert angewandt. Diese Methode heißt „Ramped Half-and-Half". Bei einer gegebenen maximalen Tiefe von N wird die Population zu gleichen Teilen in Bäume mit maximalen Tiefen von 2,3...N aufgeteilt. Jede dieser Gruppen wird zur Hälfte nach der „Growth" und zur Hälfte nach der „Full" Methode initialisiert.
2.1.3 Die Genetischen Operatoren
Die Genetischen Operatoren sind die Werkzeuge, die dem Evolutionären Algorithmus zur Verfügung stehen, um die Fitness der Population im Laufe der Evolution zu verbessern. Die am häufigsten verwendeten Operatoren sind Crossover, Mutation und Reproduktion. Der einfachste Operator ist die Reproduktion, der abhängig von der Fitness ein Individuum selektiert und eine identische Kopie in die nächste Generation überträgt. Der Crossover Operator kombiniert das genetische Material von zwei Individuen miteinander, indem er Teilbäume gegeneinander austauscht und so zwei neue Individuen erzeugt. Häufig geschieht dies so, dass Funktionen mit einer höheren Wahrscheinlichkeit ausgewählt werden als Terminale. Auch die Erzeugung nur eines Nachkommen ist gebräuchlich (vgl. (BNKF98, S. 241)).
Mutation wird auf ein einzelnes Individuum angewandt. Häufig geschieht dies im Anschluss an den Crossover Operator. Mit einer geringen Wahrscheinlichkeit wird ein zufälliger Knoten aus dem Individuum ausgesucht und der Unterbaum ab diesem Knoten durch neue, zufällige Knoten ersetzt, wie es bei der Initialisierung geschehen ist. Daneben sind auch eine Reihe anderer Genetischer Operatoren verbreitet. Banzhaf et al. etwa führen in (BNKF98, S. 242) folgende Operatoren für Mutation auf:
Point Mutation: Ein einzelner Knoten wird gegen einen zufälligen Knoten der gleichen Klasse ausgetauscht.
Permutation: Die Positionen von Argumenten einer Funktion werden vertauscht.
Hoist: Ein neues Individuum wird aus einem Unterbaum erzeugt.
Expansion Mutation: Ein Terminal wird gegen zufälligen Unterbaum ausgetauscht.
Collapse Subtree Mutation: Ein Unterbaum wird gegen ein zufälliges Terminal ausgetauscht.
Subtree Mutation: Ein Unterbaum wird gegen einen zufälligen Unterbaum ausgetauscht.
Gene Duplication: Ein Unterbaum wird durch ein zufälliges Terminal ersetzt.
Als Alternativen für den Standard Crossover Operator führt Banzhaf an gleicher Stelle folgende Operatoren auf:
Subtree Exchange Crossover: Austausch von Unterbäumen zwischen Individuen
Self Crossover: Austausch von Unterbäumen innerhalb eines Individuums
Module Crossover: Austausch zweier Module zwischen Individuen
Context-Preserving Crossover: Austausch von Unterbäumen zweier Individuen, wenn deren Koordinaten exakt übereinstimmen oder mindestens ähnlich sind.
2.1.4 Fitness Funktion
In Anlehnung an die in der natürlichen Evolution stattfindende Auslese findet in der GP ein Selektionsprozeß anhand eines Fitnesswertes statt, der jeweils einem Individuum der Population zugeordnet ist. Der Fitnesswert eines Individuums wird durch die Evaluation des Individuums durch die Fitnessfunktion ermittelt. Hierzu wird meist das genetische Programm des Individuums mit Eingaben aus einem Trainingsdatensatz ausgeführt und aufgrund der Ausgabe des Programms ein Fitnesswert bestimmt. Um ähnlich der natürlichen Evolution einen Selektionsdruck hin zu besseren Lösungen des gegebenen Problems aufzubauen, wird mittels eines Selektionsverfahrens basierend auf der Fitness der Individuen bestimmt, welche Individuen sich in die nächste Generation fortpflanzen. Eine wesentliche Anforderung sowohl an das zu lösende Problem als auch die Gestaltung der Fitnessfunktion ist die Stetigkeit der Fitnessfunktion (vgl. (BNKF98, S. 127)). Dies bedeutet, dass die Verbesserung eines Individuums bezogen auf das Problem einer entsprechenden Verbesserung des Fitnesswertes gegenüberstehen sollte. Stetigkeit der Fitnessfunktion ist wesentliche Voraussetzung dafür, dass die Individuen iterativ verbessert werden können. Eine häufig verwendete Fitnessfunktion ist die Fehler-Fitness-Funktion. Sie kann angewandt werden, wenn ein zu erreichendes Optimum bekannt ist und der noch bestehende Fehler der erreichten Lösung zu diesem Optimum bestimmt werden kann. Ein Beispiel hierfür ist etwa die symbolische Regression. Hierbei wird z.B. ein Polynom vorgegeben und das GP System soll diese Funktion so genau wie möglich durch Kombination der zur Verfügung gestellten Funktionen approximieren (vgl. (Koz92, Kapitel 10)). Mit kleiner werdender Abweichung vom vorgegebenen Polynom, steigt der Fitnesswert des Individuums.
2.1.5 Selektion
Die Selektion bestimmt, welche Individuen einer Population verbleiben bzw. sich fortpflanzen und so ihr Erbmaterial erhalten oder sogar verbreiten können. Je nach Art und Parametereinstellung des Selektions-Algorithmus kann der Selektionsdruck gesteuert werden. Ein hoher Selektionsdruck verteilt die Eigenschaften der überlegenen Individuen schnell innerhalb der Population. Dies kann dazu führen, dass der Evolutionäre Algorithmus nur eine suboptimale Lösung findet, da die vorhandene Lösung die Population dominiert und sich keine besseren Eigenschaften mehr durchsetzen können. Ein zu geringer Selektionsdruck zieht den Ablauf des Algorithmus unnötig in die Länge. Dabei kann es passieren, dass gute Eigenschaften sich nicht ausreichend schnell in der Population verbreiten können und durch die Genetischen Operatoren wieder zerstört werden.
Fitnessproportionale Selektion Fitnessproportionale Selektion war lange Zeit die am meisten verwendete Methode zur Selektion im Bereich Genetischer Algorithmen, nachdem sie von Holland eingeführt worden war (vgl. (Hol75)). Bei dieser Methode wird ein Individuum der Population per Zufall selektiert. Die Wahrscheinlichkeit ist bestimmt durch das Verhältnis der Fitness des Individuums zur Summe der Fitness aller Individuen. Blickle et al. kommen aus folgenden Gründen zu dem Schluss, dass fitnessproportionale Selektion untauglich ist (vgl. (BT95, S.40-42)):
Die Reproduktionsrate ist proportional zur Fitness eines Individuums. Wenn die Fitnesswerte nahe beieinander liegen, findet daher quasi nur eine zufällige Selektion statt.
Es herrscht keine Translations-Invarianz: Während die Fitnesswerte eins bzw. zehn noch einen großen Unterschied in der Selektionswahrscheinlichkeit bedeuten, verschwindet dieser Unterschied größtenteils, wenn man beide Fitnesswerte um einen relativ großen Wert erhöht.
Trotz hoher Varianz zu Anfang der Optimierung ist die Selektionsintensität zu gering, manchmal sogar negativ, was zu einer Verschlechterung der durchschnittlichen Fitness der Population führen kann.
Truncation Selection Truncation Selection, auch als ( |j., a)-Selektion bekannt (vgl. (Sch95, 158f)), verwendet |x Individuen als Eltern, um a neue Individuen zu generieren, von denen |x Individuen als Eltern der nächsten Generation dienen. Die absoluten Fitnesswerte spielen bei dieser Selektion keine Rolle, sondern die Reihenfolge der Individuen aufgrund der Fitnesswerte.
Selektion nach Rang Selektion nach Rang basiert ebenfalls auf der Reihenfolge der Individuen, die durch die Fitnesswerte definiert ist. Man unterscheidet lineares und exponentielles Ranking. Beim linearen Ranking hängt die Wahrscheinlichkeit, dass ein Individuum selektiert wird, linear von seinem Rang innerhalb der Population ab. Beim exponentiellen Ranking steigt die Wahrscheinlichkeit für ein Individuum, selektiert zu werden, mit seinem Rang exponentiell an.
Turnier-Selektion Bei der Turnier-Selektion tritt eine zufällig aus der Population gewählte Gruppe von Individuen gegeneinander an. Die Größe dieser Gruppe heißt die Turnier-Größe. Das Individuum der gewählten Gruppe mit dem größten Fitnesswert wird selektiert und zur Reproduktion verwendet. Der Nachkomme ersetzt die unterlegenen Individuen der Turnier-Gruppe in der Population. Die Turnier-Größe bestimmt den Selektionsdruck, wobei eine Turnier-Größe von zwei einem geringen Selektionsdruck entspricht. In der GP hat sich eine Turnier-Größe von sieben als Standard etabliert.
2.1.6 Ablauf des GP Algorithmus
Nachdem die einzelnen Komponenten des Evolutionären Algorithmus vorgestellt worden sind, folgt eine Darstellung des Ablaufes des Algorithmus.
Man unterscheidet die Generationale GP und die Steady-State GP. In der Generationalen GP bildet eine Population zu einem Zeitpunkt eine Generation, die durch die Genetischen Operatoren in die Population der nächsten Generation überführt wird:
1. Initialisierung der Population
2. Evaluation der Individuen der Population und Zuweisung eines Fitnesswertes zu jedem Individuum
3. Anwendung von Selektion und Genetischer Operatoren bis die Population der nächsten Generation vollständig ist
4. Falls das Abbruch-Kriterium des Algorithmus noch nicht erfüllt ist, fortfahren mit Punkt zwei
Im Steady-State Algorithmus werden keine Generationen unterschieden. Aus einer zufällig ausgewählten Gruppe von Individuen der Population werden mittels Turnier-Selektion die besten ermittelt. Auf diese werden die Genetischen Operatoren angewandt und mit den so entstehenden Nachfahren die Verlierer des Turniers ersetzt:
1. Initialisierung der Population
2. Zufällige Auswahl einer Gruppe von Individuen der Population für die Turnier-Selektion
3. Evaluation der Fitness der ausgewählten Individuen
4. Anwendung der Genetischen Operatoren auf die Gewinner des Turniers
5. Ersetzen der Verlierer des Turniers mit den erzeugten Nachkommen der Gewinner
6. Falls das Abbruchkriterium des Algorithmus noch nicht erfüllt ist, fortfahren mit Punkt zwei
Bei einem Vergleich von Generationaler GP und Steady-State GP anhand eines Sortierproblems kommt Kinnear zu dem Ergebnis, dass Steady-State GP bessere Resultate erzielt (vgl. (Kin93a, S. 6f)).
2.1.7 Crossover, Building Blocks und Schemata
Crossover in seinen unterschiedlichen Ausprägungen ist der hauptsächlich angewandte Genetische Operator in der GP. Die Wahrscheinlichkeit für die Wahl des Crossover Operators für die Erzeugung der Nachkommen eines Individuums liegt gewöhnlich im Bereich von 90% (vgl. (Koz92, S. 114-116)). Die starke Verwendung von Crossover in der GP wird gestützt durch die natürliche Evolution im Rahmen der biologischen sexuellen Reproduktion. Entsprechend findet Mutation während der biologischen Reproduktion zwar statt, jedoch nur in geringem Maße. Dies wird in der GP durch eine kleine Wahrscheinlichkeit für Mutation reflektiert (vgl. (BNKF98, Kapitel 2).
Der Crossover Operator wird als Grund angesehen, warum GP effektiver arbeitet als andere Verfahren, die auf rein zufälligen Veränderungen der Lösungskandidaten basieren. Wie Koza in (Koz92, S. 116-119) ausführt, enthält die Population eines GP „Building Blocks". Gute Building Blocks verbessern die Fitness der Individuen, die sie enthalten. Daher ist es wahrscheinlicher, dass diese Individuen für die Fortpflanzung selektiert werden. So gelingt es den guten Building Blocks, sich in der Population auszubreiten. Mit dieser Argumentation schließt sich Koza der Argumentation von Holland an, der die Building Block Hypothese erstmalig für Genetische Algorithmen formulierte (vgl. (Hol75)). Aufgrund dieses Ausbreitens von guten Building Blocks ist es der GP möglich, schneller gute Problemlösungen zu kreieren als dies rein mutations-basierten Verfahren möglich ist. Koza zeigt in (Koz92, Kapitel 9), dass GP bis auf sehr einfache Probleme der zufälligen Suche überlegen ist. Goldberg versucht das Funktionieren Genetischer Algorithmen mit der Building Block Hypothese zu erklären. Demnach kombiniert der Crossover Operator kleine gute Building Blocks zu größeren und besseren Building Blocks, um daraus schließlich nahezu optimale Individuen zu generieren (vgl. (Gol89, S. 41)). Die Building Block Hypothese wird z.B. von Grefenstette in (Gre93, S. 3f) als irreführend kritisiert, da sie das tatsächliche Geschehen während der evolutionären Entwicklung nur unzureichend beschreibe und leicht falsche Schlüsse gezogen werden könnten.
Die Begründung, warum GP besser funktioniert als eine rein zufällige Suche, wird von vielen Autoren mittels Schemata gegeben. Schemata sind Templates, die eine ganze Gruppe von ähnlichen Code-Abschnitten repräsentieren. Ein Schema-Theorem beschreibt Annahmen darüber, wie diese Schemata sich von Generation zu Generation weiterentwickeln, während Crossover, Mutation und Selektion auf sie einwirken. Das wohl bekannteste Schema-Theorem hat Holland für Genetische Algorithmen formuliert (vgl. (Hol75, S. 66-88)).
Den ersten Versuch, dieses Schema-Theorem auf GP zu übertragen, unternimmt Koza in (Koz92, S. 116-119). Wie Langdon in (LP02, S. 27) ausführt, wurde das Schema-Theorem von vielen Autoren inzwischen kritisiert und von einigen sogar als völlig nutzlos eingestuft. Langdon geht jedoch davon aus, dass die Überinterpretation des Schema-Theorems das Problem darstellt, nicht das Theorem an sich. Es gibt eine Reihe von Ansätzen, das Schema-Theorem auf GP zu übertragen. Eine Übersicht und eingehende Diskussion der verschiedenen Ansätze findet sich etwa in (LP02, Kapitel 3-6). Langdon führt in (LP02, Kapitel 6) das „macroscopic exact schema theorem" ein und zeigt, dass Standard-Crossover Schemata höherer Ordnung zusammengesetzt werden aus Schemata niedriger Ordnung. Er räumt jedoch ein, dass der Begriff „Building Block" für diese Schemata niedriger Ordnung insofern missverständlich für GP ist, als er suggeriert, daß Building Blocks Schritt für Schritt zu besseren und größeren Blöcken zusammengesetzt werden. Wie Langdon ausführt, legt sein Schema-Theorem nahe, dass der Auswahl-Prozess der verwendeten Schemata nicht reproduzierbar ist und zufällig stattfindet. Des weiteren werden nicht notwendigerweise nur Schemata ausgewählt, die besonders kurz oder überdurchschittlich fit sind.
2.1.8 Ansätze gegen Makromutation
Ein wesentliches Problem des Crossover Operators im Vergleich zu seinem Vorbild in der biologischen Reproduktion ist, dass er zwar einerseits gute Kombinationen schafft, andererseits aber als Makromutation arbeitet und erstellte Building Blocks wieder zerstört. In der biologischen Reproduktion wird viel Energie darauf verwendet, einmal erstellte gute Building Blocks vor den schädlichen Einflüssen des Crossover zu schützen. Biologisches Crossover ist homolog, d.h. das Crossover findet fast ausschließlich auf Gen-Ebene statt. Es kommt kaum vor, das zwei Gene mit vollkommen unterschiedlichem Zweck gegeneinander ausgetauscht werden (vgl. (BNKF98, S. 156f).
Es gibt inzwischen eine Reihe von Ansätzen, zu versuchen, Schutzmechanismen vor der Makromutation in der GP einzuführen. Ein natürlich auftretendes Phänomen ist die Anlagerung von auswirkungsfreiem Code an die Building Blocks im Laufe der Simulation. Hierdurch wird die Wahrscheinlichkeit geringer, dass die Building Blocks zerstört werden. Diesen Vorgang kann man auch beim natürlichen Vorbild beobachten. Über 90% des Genoms höherer Lebewesen bestehen aus sog. Introns, die weder Gene kodieren noch Kontrollsequenzen enthalten. Während der EA läuft, kann man beobachten, dass die Menge an auswirkungsfreiem Code exponentiell zunimmt (BNKF98, S. 191-193). Dieses Phänomen wird als „Bloat" bezeichnet. Neben der Schutzfunktion durch die Introns hat Bloat jedoch das Problem, dass dadurch die Entwicklung gehemmt wird und die Ausführungszeit des erzeugten Programms unnötig in die Länge gezogen wird.
Banzhaf identifiziert die Makromutation des Crossover Operators als großen Unterschied zu dem natürlich vorkommenden Crossover bei der biologischen sexuellen Reproduktion. In der Natur sind beinahe alle Crossover erfolgreich, wogegen in der GP ca. 75% nach biologischen Maßstäben als „tödlich" einzustufen wären (vgl. (BNKF98, S. 157)). Die Eindämmung der Makromutation des Crossover Operators in der GP ist daher ein wichtiger Forschungsbereich. Im Folgenden werden einige der Ansätze angesprochen, die zur Verbesserung des Crossover Operators bzw. zur Vermeidung seiner negativen Auswirkungen untersucht wurden.
Brood Recombination Tackett schlägt in (Tac94, Kapitel 5) mit der „brood recombination" eine Methode vor, die den Crossover Operator zwar nicht verbessert, aber negative Auswirkungen eindämmt. In der Natur haben einige Spezies wesentlich mehr Nachkommen als zum Überleben der Art notwendig wären. Einige Nachkommen sterben bald nach der Geburt aufgrund verschiedener Mechanismen, etwa im Kampf miteinander um Nahrung. Dadurch wird sichergestellt, dass die Eltern die für die Aufzucht notwendige Energie nur in die aussichtsreichsten Nachkommen investieren.
Tackett überträgt diesen Ansatz auf GP. Statt nur ein oder zwei Nachkommen zu erzeugen, wird eine ganze Reihe von Nachkommen generiert. Für diese Gruppe, genannt Brut, werden die Fitnesswerte berechnet und die besten ein oder zwei Nachkommen ausgewählt. Der Rest der Brut wird verworfen. Um den erhöhten Rechenanforderungen dieser Methode entgegenzuwirken, schlägt Tackett vor, die Fitness Berechnung für die Brut nicht mit den gesamten Trainingsdaten vorzunehmen, sondern nur mit einem kleinen Teil. Er begründet die Legitimität dieses Vorgehens damit, dass es das Ziel ist, die untauglichen Individuen auszusortieren und nicht das tatsächlich beste Individuum der Brut zu finden (vgl. (Tac94, S. 87)). Tackett berichtet, dass die erwartete Verbesserung gegenüber GP ohne Brut-Selektion bei den durchgeführten Versuchen tatsächlich eingetreten ist.
Neben Ansätzen zur Umgehung der schädlichen Auswirkungen von Crossover gibt es zahlreiche Versuche, den Crossover Operator „intelligenter" zu machen.
Strong Context-Preserving Crossover D'haeseleer entwickelt in (D'h94) den „strong context-preserving crossover" (SCPC) Operator, der Crossover nur zwischen Knoten zulässt, die an genau derselben Position zweier Eltern sind. D'haeseleer berichtet, durch Mischung von normalem Crossover und SCPC Verbesserungen erzielt zu haben. Die alleinige Verwendung von SCPC würde Probleme erzeugen, da dadurch die Vielfältigkeit innerhalb der Population leiden würde. Einen gewissen Grad an Makromutation hält D'haeseleer für nötig (vgl. (D'h94, S. 2)).
Explicit Multiple Gene Systems Altenberg stellt in (Alt95) ein System vor, in dem Fitness-Komponenten von einer Teilmenge vorhandener Gene beeinflusst werden. Während der Evolution wird periodisch versucht, ein neues Gen hinzuzufügen. Dieses wird jedoch nur integriert, wenn dadurch die Fitness steigt. Während der Evolution der Population werden per Crossover Gene zwischen den Individuen ausgetauscht. Die von Altenberg vorgeschlagene „Konstruierende Selektion" (vgl. (Alt95, S. 39)) mit anschließendem Austausch von Genen durch Crossover zeigt eine starke Ähnlichkeit zum homologen biologischen Crossover. Statt zuzulassen, dass durch die Makromutation des Crossover ein großer Teil der guten Building Blocks zerstört wird, wird in diesem Modell das Crossover auf Gene bestehend aus einem oder mehreren Building Blocks beschränkt. Da keine Gefahr besteht, dass Building Blocks zerstört werden, ist Bloat vermutlich kein Problem bei diesem Ansatz.
Explicitly Defined Introns Zu interessanten Maßnahmen gegen die Makromutation durch den Crossover Operator gehört unter anderem der Ansatz „explicitly defined introns" (EDI). Zwischen je zwei Knoten eines GP Baumes wird ein ganzzahliger Wert gespeichert, der sich auf die Berechnung des Baumes nicht auswirkt. Der Crossover Operator wird verändert, so dass die Wahrscheinlichkeit eines Crossover-Ereignisses zwischen zwei Knoten von dem Wert des EDI zwischen ihnen abhängt. Im Laufe der Evolution werden die EDIs genauso wie der Rest des Individuums evolutionär entwickelt. Hierdurch bilden sich Building Blocks, die durch die sie verbindenden EDIs vor dem Crossover geschützt werden. Nordin et al. führen in (NFB95, S. 16) eine Reihe von Tests durch, die den Schluss nahelegen, dass EDIs eine wichtige Rolle im Auffinden von Individuen hoher Fitness spielen. Was Fitness, Generalisation und Rechenzeit angehen, haben Individuen mit EDIs besser abgeschnitten als solche Individuen in Tests ohne EDIs.
GP 1-Point Crossover Operator Poli und Langdon schlagen in (PL98, S. 1319) einen 1-Punkt Crossover Operator vor, der für die Wahl eines geeigneten Crossover Punktes strukturelle Ähnlichkeiten in den Elternbäumen berücksichtigt. Ihre Experimente weisen darauf hin, dass sich dadurch im Laufe der Evolution die zerstörerischen Einflüsse des Crossover abschwächen lassen.
2.1.9 Modularisierung
In vielen Programmiersprachen gibt es die Möglichkeit, Programmteile zusammenzufassen und diese Module an anderer Stelle zu verwenden. Modularisierung dient der Abstraktion, dem Aufteilen eines Problems in Unterprobleme und der Wiederverwendbarkeit des Programmcodes. Aber auch im Zusammenhang mit dem Problem der Makromutation durch den Crossover Operator ist Modularisierung interessant. Einige Ansätze verwenden spezielle Crossover Operatoren, welche die Module berücksichtigen und so der Makromutation verbeugen. Modularisierung wurde in der GP von verschiedenen Autoren untersucht. Eine Auswahl verschiedener Techniken wird im Folgenden dargestellt.
Encapsulation Die Idee der Encapsulation (Einkapselung) beschreibt Koza in (Koz92, S. 110-112). Es handelt sich dabei um einen asexuellen Genetischen Operator, der einen Funktionsknoten eines Individuum auswählt und ihn durch einen Terminalknoten ersetzt, der den Unterbaum des ausgewählten Funktionsknoten enthält. Das erzeugte Terminal kann nun auch in anderen Individuen angewandt werden. Der eingekapselte Unterbaum kann durch den Crossover Operator nicht mehr verbessert oder zerstört werden. Wenn der ersetzte Unterbaum einen nützlichen Code enthält, könnte dies von Vorteil sein.
Module Acquisition Angeline und Pollack schlagen eine „module acquisition" genannte Technik vor (vgl. (AP92, S. 2-4)), um wiederverwendbare Module zu erzeugen. In einem ausgewählten Individuum wird dazu ein Unterbaum bis zu einer festgelegten Tiefe als Modul definiert. Die Teile des Unterbaums unter dem Modul werden als Argumente des Moduls betrachtet. Neben der ausschließlichen Verwendung innerhalb des Individuums kann das Modul über eine Funktionsbibliothek der gesamten Population zur Verfügung gestellt werden. Solange mindestens ein Individuum ein Modul verwendet, verbleibt es in der Bibliothek, ansonsten wird es gelöscht.
Genau wie bei der Encapsulation wird bei der Module Acquisition ein einmal definiertes Modul nicht mehr weiter entwickelt und ist vor der Makromutation des Crossover geschützt.
Automatically Defined Functions Koza beschreibt „automatically defined functions" (ADF) in (Koz92, S. 534ff) und sehr ausführlich in (Koz94, Kapitel 4-16). Um ADFs in der GP zu verwenden, werden die Programmbäume in zwei Teile aufgeteilt: einen Ast, der zur Berechnung der Fitness ausgewertet wird und einen Ast, der die Funktionsdefinitionen der ADFs enthält. Beide Äste nehmen an der Evolution teil. Der Crossover Operator muss dabei die spezifischen Besonderheiten der Äste und ihre Beziehung miteinander berücksichtigen. Die Definition einer ADF im Funktionsdefinitionsast des Programmbaumes besteht aus drei Teilen: Dem Funktionsnamen, einer Argumentenliste sowie einem Ast, der den Körper der Funktionsdefinition enthält. Der Funktionsname der ADF wird Teil der Funktionenmenge des Resulate erzeugenden Astes. Die in der Argumentliste definierten Variablen werden Teil der Menge der Terminale ihres ADF Funktionskörpers. Die Evolution findet ausschließlich im Funktionskörper der ADF und in dem Resultate erzeugenden Ast statt. Nur dieser Ast sowie der Funktionskörper der ADFs werden per Zufall erzeugt. Bevor die Evolution beginnen kann, müssen die Anzahl und Namen der ADF sowie die Anzahl und Namen der Funktionsargumente für jedes ADF festgelegt werden.
À Abstraktion Yu stellt in (Yu99a, Kapitel 6,7) einen Ansatz vor, À Abstraktionen, basierend auf dem À Kalkül, in der GP anzuwenden. Jede À Abstraktion wird dabei innerhalb des GP Baums als unabhängiges Modul betrachtet und als eine Einheit während des evolutionären Prozesses geschützt. Diese Module entwickeln sich auf ähnliche Weise wie der restliche GP Baum. Crossover ist nur zwischen Modulen erlaubt, die gleiche Anzahl und Typ der Ein- und Ausgaben besitzen. Den Erfolg dieses Ansatzes dokumentiert Yu z.B. in (Yu99b). Ein Grund für seinen Erfolg könnte auf den Struktur und Funktion erhaltenden homologen Crossover im Zusammenhang mit der λ Abstraktion zurückzuführen sein.
2.1.10 Weitere Verbesserungsansätze
Weitere interessante Ansätze zur Erweiterung der Standard-GP sind u.a. die folgenden:
Schleifen und Rekursion Obwohl Schleifen und Rekursion in der manuellen Programmierung eine enorme Bedeutung haben, ist ihre Anwendung in der GP mit Schwierigkeiten verbunden. Lange Schleifen, insbesondere Endlosschleifen, können die Evolution eines Programmes zum Erliegen bringen. Eine mögliche Herangehensweise beschreibt Kinnear in (Kin93b, S. 5) im Rahmen der evolutionären Entwicklung eines Sortieralgorithmus: Die verwendete Schleife kann als Parameter nur Start- und End-Index einer endlich großen Liste erhalten.
Strongly Typed Genetic Programming Die Erweiterung der traditionellen GP zum stark typisierten GP (STGP) führt Typen für Terminale und Funktionen in die Genetische Programmierung ein (Mon93, S. 7). Diese Erweiterung ist besonders sinnvoll, da sie den Suchraum des Evolutionären Algorithmus erheblich einschränkt. Funktionen werden bestimmten Ein- und Ausgabetypen zugeordnet und können nur noch mit Terminalen des passenden Typs kombiniert werden.
Cultural GP Die Cultural GP, die von Spector und Luke beschrieben wird (SL96), verwendet einen indizierten Speicher, auf den alle Individuen der Population über die Generationen hinweg Zugriff haben. Der Speicher wird am Anfang der evolutionären Entwicklung initialisiert und steht der Population anschließend als Datenspeicher und Kommunikations-Medium zwischen den Generationen zur Verfügung. Die Autoren kommen zu dem Resultat, dass durch den gemeinsam verwendeten Speicher der Berechnungsaufwand bei den betrachteten Problemen im Vergleich zur Standard-GP sinkt.
2.2 Künstliche Neuronale Netze
Im Kontext der Entscheidungsfindung für Finanzmarkt-Transaktionen werden Künstliche Neuronale Netze (KNN) verbreitet eingesetzt. Ihr Einsatz reicht von Trendprognose-Systemen, wie z.B. in (MK, S. 2-7) für den Goldmarkt beschrieben, über Punktprognosesysteme, wie z.B. in (NM02, S. 501511) für den Währungsmarkt vorgeschlagen, bis zur Entwicklung von automatischen Handelssystemen, wie etwa in (Ska01, S. 2-8) dargestellt. Wegen der weiten Verbreitung und der vielen erfolgreichen Anwendungen werden im Folgenden die Grundlagen von KNN kurz dargestellt.
Künstliche Neuronale Netze (KNN) sind motiviert durch das natürliche Gehirn. Dabei steht nicht die biologisch korrekte Simulation eines Gehirns im Vordergrund, sondern die Simulation der mathematisch relevanten Elemente auf einer abstrakten Ebene.
Die wesentlichen Teile, die für eine Simulation eines KNN zu definieren sind, sind die Neuronen, die Verbindungen zwischen den Neuronen sowie die Methode, nach der das Netz trainiert wird. Diese Komponenten und häufig verwendete Netztopologien werden im Folgenden vorgestellt. Diese Ausführungen orientieren sich an der Schilderung von Zell (Zel94, Kapitel 5-8).
2.2.1 Bestandteile neuronaler Netze
Neuronen Die Neuronen sind charakterisiert durch:
den Aktivierungszustand, der den aktuellen Grad der Aktivierung des Neurons angibt.
den Schwellwert, der in die Aktivierungsfunktion zur Berechnung des nächsten Aktivierungszustandes eingeht. Er gibt in vielen Modellen die Schwelle an, ab der ein Neuron stark aktiviert ist. In biologischen Neuronen entspricht dies der Reizschwelle, die erreicht werden muss, damit das Neuron feuert.
die Aktivierungsfunktion, die einen neuen Aktivierungszustand berechnet aus dem aktuellen Aktivierungszustand, der Eingabe durch andere Neuronen sowie dem Schwellwert des Neurons.
die Ausgabefunktion, die aus der aktuellen Aktivierung des Neurons einen Ausgabewert ermittelt.
Verbindungsnetzwerk Infolge der Abstraktion vom natürlichen Vorbild werden im KNN nicht die im biologischen Gehirn zu findenden Axons, Dendriten und Synapsen simuliert, sondern die Verbindung zwischen jeweils zwei Neuronen auf einen Wert, das Verbindungsgewicht, reduziert. Insgesamt wird das Verbindungsnetzwerk zwischen den Neuronen häufig durch eine Matrix von Verbindungsgewichten dargestellt. Durch den Wert des Verbindungsgewichtes zwischen zwei Neuronen wird die Stärke der Verbindung zwischen diesen charakterisiert. Das Gewicht kann je nach Modell in verschiedenen Wertebereichen liegen. Neben positiven Werten der Gewichte steht der Wert 0 für eine nicht vorhandene Verbindung und negative Werte für hemmende Verbindungen, welche die Aktivierung des folgenden Neurons abschwächen. Während der Simulation eines KNN werden die Ausgabewerte aller Neuronen, die mit dem betrachteten Neuron verbunden sind, diesem mit den Verbindungsgewichten gewichtet als Eingabe zur Verfügung gestellt. Innerhalb des betrachteten Neurons werden diese gewichteten Eingaben in der Aktivierungsfunktion verarbeitet. Meist werden während der Lernphase nur die Verbindungsgewichte verändert. Das erlernte Wissen ist auf das Netzwerk der Verbindungsgewichte verteilt und es ist nicht ohne weiteres möglich, einzelne Aussagen abzuleiten. Einige Autoren, wie z.B. Gruau in (Gru94, S. 8, S. 22), sehen vor, auch Komponenten des Neurons wie Aktivierungsfunktion oder Schwellwert während der Lernphase änderbar zu halten.
2.2.2 Netztopologien
KNN sind häufig schichtenweise organisiert, mit einer Eingabe-, einer Ausgabe- und mindestens einer Zwischenschicht. Über die Ein- und Ausgabeschicht erfolgt die Kommunikation mit der Umgebung, während in den internen Schichten die Informationsverarbeitung stattfindet.
Beim topologischen Aufbau von KNN wird im Wesentlichen zwischen Netzen mit und ohne Rückkopplung unterschieden. Unter Rückkopplung versteht man, dass es Neuronen gibt, für die ein Pfad durch das Netz existiert, der wieder zu diesem Neuron zurückführt.
2.2.3 Lernmethoden
Nachdem man sich für eine bestimmte Netztopologie für ein gegebenes Problem entschieden hat, werden die Verbindungsgewichte typischerweise mit zufälligen Werten initialisiert. In dieser Ausgangssituation wird das KNN das gegebene Problem in den seltensten Fällen zufriedenstellend lösen. Daher ist es notwendig, die Verbindungsgewichte zu ändern, so dass eine bessere Lösung des Problems erreicht wird. Diesen Vorgang nennt man Training. Es gibt verschiedene Lernmethoden, um das Training durchzuführen. In der Literatur finden sich viele verschiedene Ansätze, um ein KNN für die gegebene Aufgabe zu trainieren. Die theoretisch veränderbaren Komponenten eines KNN sind die Verbindungsgewichte, Schwellwert, Aktivierungsfunktion, Ausgabefunktion sowie das Hinzufügen oder Löschen von Neuronen. Unter den umfassendsten Ansätzen, die alle diese möglichen Änderungen einschließen, findet sich z.B. der von Gruau in (Gru94, Kapitel 2-3). Dort kodieren genetisch entwickelte Programme den Aufbau und die Bestandteile des KNN. Wird ein solches Programm auf ein Ausgangsneuron angewandt, entsteht daraus durch die Ausführung der Befehle des Programmes nach und nach das KNN. Zu den Befehlen gehören Anweisungen zur Teilung eines Neurons in zwei Neuronen, Löschen von Neuronen, das Erstellen und Löschen von Verbindungen zwischen Neuronen, das Ändern von Verbindungsgewichten und einige Operationen mehr.
Arten des Lernens Viele Anwendungen beschränken sich darauf, ausschließlich die Verbindungsgewichte einer vorgegebenen Netztopologie zu trainieren. Hierbei unterscheidet man Arten des Lernens nach den zur Verfügung gestellten Trainigsdaten:
Während des überwachten Lernens werden dem KNN gleichzeitig Ein- und Ausgabe-Daten präsentiert und durch das Lernverfahren die Gewichte so verändert, dass das Netz nach einigen Durchgängen die Assoziation dieser Datensätze selbstständig vornehmen kann. Ziel ist, dass geringfügig veränderte Eingabedaten richtig klassifiziert werden und so eine Generalisierung durch das KNN erreicht wird.
Beim bestärkenden Lernen werden dem KNN nur Eingabedaten zur Verfügung gestellt und nach der Auswertung durch das KNN mitgeteilt, ob die Klassifizierung durch das Netz richtig oder falsch ist.
Das unüberwachte Lernen zeichnet sich dadurch aus, dass Lernen durch Selbstorganisation geschieht. Das verwendete Lernverfahren sorgt dafür, dass ähnliche Eingabemuster in eine Klasse eingeteilt werden, die durch ein oder mehrere Neuronen dargestellt werden. Bei dieser Art des Lernens werden statistische Eigenschaften der Eingabemuster extrahiert und darauf basierend generalisierende Klassen gebildet. Interessante Arbeiten aus diesem Bereich sind unter anderem Learning-Vector- Quantisation (LVQ) oder selbstorganisierende Karten von Kohonen (vgl. (Koh89, Kapitel 5)) sowie die wachsenden Zellstrukturen (Fri92) bzw. das wachsende Neuronale Gas (Fri95) von Fritzke.
Hebbsche Lernregel Die Grundlage vieler Lernregeln wurde in ihrer ersten Form bereits 1949 von Donald O. Hebb formuliert und nach ihm die Hebbsche Lernregel benannt: Wenn ein Neuron von einem anderen Neuron eine Eingabe erhält und beide gleichzeitig stark aktiviert sind, so erhöht sich das Gewicht der Verbindung zwischen diesen Neuronen (vgl. (Zel94, S. 84)). Die Größe der Änderung des Gewichts wird Lernrate genannt. Sie wird entweder konstant vorgegeben oder geht aus einer Funktion hervor, die berücksichtigt, dass zu Beginn eines Lernvorganges eine hohe Lernrate vorteilhaft ist, gegen Ende des Trainings die Größe der Änderungen jedoch abnehmen sollte. Hierdurch kann ein Konvergieren des KNN in einen optimalen Zustand herbeigeführt werden.
Backpropagation-Regel Eine weit verbreitete Lernregel für überwachtes oder bestärkendes Lernen ist die Backpropagation-Regel (vgl. (Zel94, S. 99114)). Sie ist eine Verallgemeinerung der sog. Delta-Lernregel , die nur für einstufige Netze mit linearen Aktivierungsfunktionen verwendbar ist. Netze mit linearen Funktionen als Aktivierungsfunktion können nur lineare Funktionen berechnen. Mehrschichtige Netze sind mächtiger als einschichtige Netze. Für sie wird üblicherweise das Backpropagation-Verfahren bzw. eine ihrer Weiterentwicklungen verwendet, da es in der Lage ist, Netze mit semilinearen Aktivierungsfunktionen und mehreren Schichten zu trainieren. Beim Backpropagation-Verfahren wird nach Anlegen von Eingabe- und Ausgabedaten an das Netz der noch vorhandene Fehler zwischen vorgegebener Ausgabe und tatsächlicher Ausgabe bestimmt und gewichtet durch die Verbindungsgewichte rückwärts durch das Netz gesendet, wobei jeweils die Gewichte der Verbindungen abhängig von der Lernrate so geändert werden, dass der Fehler kleiner wird.
2.3 Handelssysteme
Nachdem die Grundlagen Neuronaler Netze und Evolutionärer Algorithmen erläutert wurden, wird im Folgenden in das Anwendungsgebiet eingeführt. Zunächst wird auf Handelssysteme im Allgemeinen eingegangen, danach betrachtet, wie mechanische Handelssysteme im Speziellen aufgebaut sind. Anschließend wird die Frage der Positionsgrößen-Bestimmung eines Handelssystems diskutiert und im Anschluss verschiedene Maße für den Vergleich von Handelssystemen dargestellt.
In der Literatur gibt es verschiedene Auffassungen, was ein Handelssystem kennzeichnet. Im Rahmen dieser Arbeit ist unter einem Handelssystem ein Regelwerk zu verstehen, durch das festgelegt ist, unter welchen Umständen der Benutzer des Handelssystems bestimmte Aktionen am Kapitalmarkt veranlasst. Hat sich der Benutzer des Systems auf ein Handelssystem festgelegt, ist ihm die Entscheidungsfindung abgenommen und er muss lediglich noch ausführen, was das Handelssystem vorschlägt. Wenn der Benutzer selbst die Regeln überprüfen muss, spricht man von einem manuellen Handelssystem bzw. von einem diskretionären Händler. Neben Handelssystemen, die mehr oder weniger konkrete Handelsempfehlungen geben, findet man Prognose-Systeme, die versuchen, etwa den Kurs eines Wertpapiers zu einem zukünftigen Zeitpunkt vorauszusagen. Ob und wie der Benutzer aufgrund dieser Prognose handelt, bleibt ihm überlassen. Die Ausführung der Empfehlungen des Handelssystems durch den Menschen ist fehleranfällig und kostet Zeit. Daher hat sich mit dem Aufkommen leistungsfähigerer Rechner der Handel mittels automatisierter Handelssysteme, der „mechanischen Handelssysteme", die keine Eingriffe des Benutzers erfordern, verbreitet. Dem Benutzer eines automatisierten Handelssystems, dem sog. „systematischen Händler", obliegt lediglich noch eine übergeordnete überwachende Funktion. Vince hält den Einsatz eines voll automatisierten Handelssystems sogar für unabdingbar, da sich sonst schwer sicherstellen lässt, dass die optimale Positionsgröße gehandelt wird (vgl. (Vin90, S. 41, S. 116)). Um zu überprüfen, ob ein mechanisches Handelssystem funktioniert, wird ein sog. Backtesting durchgeführt. Dabei werden dem Handelssystem historische Daten präsentiert und aufgrund der Entscheidungen des Handelssystems eine Auswertung vorgenommen, ob der reale Einsatz möglich ist.
Bei der Entwicklung eines Handelssystems für ein betrachtetes Wertpapier muss auch die Frage beantwortet werden, wie groß die Position sein soll, die von diesem Wertpapier zu jedem Zeitpunkt gehalten wird. Im Grunde stellt das Handelssystem eine Funktion dar, die für jeden Zeitpunkt z.B. positive Werte für eine entsprechend große Position des Wertpapiers, negative Werte für eine entsprechende leerverkaufte Menge des Wertpapiers oder Null für keine Position in diesem Wertpapier liefert. Das Problem wird in mehrere Teile unterteilt. Neben der Selektion eines passenden Wertpapiers steht das „Market Timing", das angibt, wann eine Position eingegangen oder aufgelöst werden soll und das „Position Sizing", das angibt, wie groß die einzugehende Position sein soll. Viele Autoren beschränken sich darauf, das Market Timing zu optimieren und lassen das mindestens ebenso wichtige Position Sizing fast vollständig außen vor (vgl. (Tha99, S. 6f)). Dabei ist es, wie Vince herausstellt, leicht möglich, trotz eines guten Market Timings wegen schlechten Position Sizings schwere Verluste zu erleiden bzw. kaum Rendite zu erwirtschaften. Demgegenüber ist nur ein Market Timing mit geringfügig positivem Erwartungswert nötig, um auf lange Sicht erhebliche Gewinne zu ermöglichen, wenn das Position Sizing richtig durchgeführt wird. Das zu handelnde Wertpapier wird als gegeben vorausgesetzt. Daher wird die Selektion des zu handelnden Wertpapiers im Folgenden nicht betrachtet.
2.3.1 Tape Reader
In seinem erstmalig 1919 publizierten und 2001 neu aufgelegten Buch (Wyc01, Kapitel 4-12) schildert Wyckoff seine Methode, als Tape Reader an der New Yorker Börse Geld zu verdienen. Zu dieser Zeit wurden die aktuellen Kursfestellungen und Kauf-/Verkaufgebote noch per sog. Ticker an die Händler weitergeleitet und dort auf ein Band (engl. Tape) ausgedruckt. Heute ist davon noch die Bezeichnung Tick geblieben als Ausdruck für eine einzelne Kursfestellung. Tape Reader fällten ihre Handelsentscheidungen ausschließlich aufgrund der Kursdaten, die ständig auf ihrem Band einliefen, und waren damit teilweise sehr erfolgreich. Wie Levere in (LeF23, Kapitel 2) berichtet, gehörte der zu seiner Zeit sehr bekannte Spekulant Livermore ebenfalls zu den erfolgreichen Anwendern des Tape Reading.
Laut (Wyc01, S. 9) waren Kursrelevante Meldungen bereits Minuten, Stunden und sogar Tage vorher auf dem Band des Tickers zu lesen, bevor die Meldungen in der Presse erschienen. Wyckoff erklärt dies mit dem Handeln von besser informierten Investoren, bevor eine Nachricht an die Öffentlichkeit gegeben wurde. Voraussetzung war, dass der Tape Reader sich darauf verstand, die Daten des Bandes richtig zu interpretieren. Die Tape Reader stellten alleine aufgrund einer Reihe von Preis-Feststellungen einen übergeordneten Trend fest und schlossen sich diesem an. Hierzu bedurfte es einiger Erfahrung sowie des ständigen Beobachtens des Marktes, d.h. einer Vielzahl von Wertpapieren gleichzeitig.
Welche Prozesse genau im Gehirn eines Tape Readers ablaufen und zu Kauf- bzw. Verkaufs-Entscheidungen führen, ist nicht zu sagen. Es ist schwer, aus einem neuronalen Netz Regeln zu extrahieren, ohne das gesamte Netz zu simulieren, da die Information über das gesamte Netz verteilt ist. Selbst wenn der Tape Reader nach bestem Gewissen versuchte, die zu Grunde liegenden Regeln darzustellen, ist es sehr gut denkbar, dass sich jemand, der sich nur nach den Regeln verhält, in einigen Fällen anders entscheidet als der Tape Reader selbst.
Im Gegensatz zu den Tape Readern, welche die gesamte Informationsverarbeitung der Kurse im Kopf durchführen mussten, stehen heutigen Händlern rechnergestützte Vorverarbeitungen der Marktdaten zur Verfügung. Sehr verbreitet sind verschiedene Formen von Kurs/Zeit-Diagrammen, genannt Charts, an denen z.B. Trends oder Widerstands- und Unterstützungs-Bereiche einer Kursbewegung abzulesen sind. Häufig in diese Charts integriert findet man verschiedene Zeit-Reihen, die aus den Kurs-Daten abgeleitet sind, sog. technische Indikatoren. Neben diesen aus den Kursen abgeleiteten Zeit-Reihen verwenden Investoren noch eine ganze Reihe von zusätzlichen Daten, aus denen auf die unterschiedlichste Weise versucht wird, die aktuelle Markt-Meinung herauszulesen. Im Folgenden sollen nur die direkt aus den Kurs-Daten abgeleiteten technischen Indikatoren näher betrachtet werden. Die Charts stellen ein grafisches Hilfsmittel dar und die zusätzlichen Marktdaten sind, wie die Tape Reader gezeigt haben, nicht unbedingt notwendig, da die wesentlichen Informationen bereits in den Kurs-Daten vorhanden sind.
2.3.2 Market Timing
Market Timing nennt man die Entscheidungsfindung, ob zu einem bestimmten Zeitpunkt eine Position in einem Wertpapier eingegangen oder aufgelöst wird. Zusätzlich können mithilfe verschiedener Indikatoren Kursziele zur Gewinnmitnahme (Take Profit) sowie Kurse zur Verlustbegrenzung (Stoploss) festgelegt werden. Take Profit und Stoploss werden häufig zusammen mit der Order zum Eröffnen der Position gegeben.
Den Tape Readern standen nur die reinen Kursinformationen zur Verfügung, auf denen basierend sie ihre Entscheidungen trafen. Jedoch haben Händler schon früh Charts als einfache Veranschaulichung der Kursentwicklung verwendet. Basierend auf in den Charts erkennbaren Widerständen, Unterstützungen, Trends und verschiedenen Formationen der Kursentwicklung entwickelte Dow die sog. Dow-Theory, die z.B. in (Mur99, S. 23-33) diskutiert wird. Diese Form der (Chart-)Technischen Analyse eines Wertpapiers wird bis heute noch angewandt. Zusätzlich wurden im Laufe der Zeit viele Technische Indikatoren entwickelt, die bei der Interpretation der Kursdaten unterstützen und häufig sogar eine direkte Ableitung von Handelssignalen erlauben sollen.
Technische Indikatoren Technische Indikatoren stellen eine Vorverarbeitung der reinen Kursinformationen dar. Jedem Indikator liegt eine gewisse Sichtweise und Annahmen über den Markt zu Grunde, die durch den Entwickler des Indikators festgelegt wurden. Eine übersicht über viele Indikatoren ist z.B. in (Mue93) bzw. (Flo00) zu finden. Bei den technischen Indikatoren unterscheidet Florek Trendfolger, Momentum-Oszillatoren, Trendbestimmungs-Indikatoren sowie Volatilitäts-Indikatoren und stellt für diese Klassen die historische Entwicklung und Unterschiede zwischen den Indikatoren dar. Allen Indikatoren gemein ist, dass sie gewisse statistische Eigenschaften der historischen Kursdaten darstellen. Die Autoren der Indikatoren knüpfen an bestimmte Konstellationen des Indikatorverlaufs Handlungsanweisungen. Der Gedanke dabei ist, dass sich die Marktteilnehmer in ähnlichen Situationen wieder ähnlich verhalten und diese Muster über die Indikatorkonstellation erfasst werden. Neben profitablen Signalen eines Indikators gibt es immer wieder Zeiten, in denen der Indikator Fehlsignale erzeugt. Dies könnte z.B. passieren, wenn ein Markt von einem Trend in eine Seitwärtsbewegung übergeht. Ein ständiges Überprüfen der verwendeten Indikatoren ist daher unerlässlich.
Die Funktionsweise eines technischen Indikators wird im Folgenden anhand des Aufbaus von gleitenden Durchschnitten dargestellt und der aus diesen aufgebaute Trendfolger MACD exemplarisch beschrieben.
Gleitende Durchschnitte Gleitende Durchschnitte berechnen für jeden Zeitpunkt einer Kurszeitreihe einen Wert, der die Informationen eines festgelegten Zeitfensters der jüngsten Vergangenheit auf einen Wert verdichtet und so einen repräsentativen Wert für dieses Zeitfenster von Kurswerten darstellt. Man unterscheidet sie nach der Berechnung des Durchschnitts durch ihre sog. Kernelfunktion (vgl. (GBD+00, S. 10f)). Zu den weit verbreiteten Durchschnitten gehören der „simple moving average" (SMA), dessen Kernelfunktion das arithmetische Mittel der Kurse im Zeitfenster berechnet, sowie der „exponential moving average" (EMA), dessen Kernelfunktion eine exponentiell wachsende Kurve ist und daher Kurse aus der jüngsten Vergangenheit stärker gewichtet als ältere Kurse. Eine Diskussion verschiedener Gleitender Durchschnitte und der Vor- und Nachteile verschiedener Kernelfunktionen findet sich bei Ehler in (Ehl01, Kapitel 3). Bereits ohne weitere Schritte sind Gleitende Durchschnitte ein sehr häufig verwendeter technischer Indikator. Sie sind nützliche Hilfsmittel bei der Analyse eines Kursverlaufes, indem sie als Widerstands- und Unterstützungszonen interpretiert werden und diese innerhalb eines Charts grafisch sichtbar machen. Neben dieser direkten Interpretation werden sie jedoch häufig als Grundlage zur Berechnung von anderen technischen Indikatoren verwendet.
MACD Der „moving average convergence divergence" (MACD) ist einer der am weitesten verbreiteten Indikatoren und wird häufig in der Literatur diskutiert, z.B. von Florek in (Flo00, S. 192f), der die Interpretationsmöglichkeiten sowie Vor- und Nachteile des MACD darstellt. Dieser wurde von Gerald Appel 1979 vorgestellt und berechnet sich aus der Differenz zweier EMAs. Als Standard für die Größe der Zeitfenster dieser EMAs haben sich die letzten 12 bzw. 26 Preisfeststellungen etabliert. In Kurzschreibweise wird dies als EMA(12) bzw. EMA(26) angegeben. Der MACD gehört zu den TrendfolgeIndikatoren und zeigt in der Standardinterpretation einen Aufwärtstrend der zugrundeliegenden Kurse an, solange er steigt bzw. einen Abwärtstrend, solange er fällt. Um Kauf- und Verkaufssignale zu erzeugen, wird zusätzlich aus der MACD-Zeitreihe ein EMA(9) berechnet, der als Signallinie dient. Schneidet der MACD die Signallinie im Chart von unten nach oben, so wird dies als Kaufsignal gewertet. Ein Schneiden von oben nach unten wird entsprechend als Verkaufssignal interpretiert.
Mit dieser Standardinterpretation ist bereits ein einfaches Handelssystems beschrieben. In Markt-Trends einer passenden Periode kann es erfolgreich sein. Ändert sich die Periode ungünstig oder geht der Markt in einen Seitwärtstrend über, wäre eine Anpassung bzw. Kombination mit anderen Indikatoren notwendig.
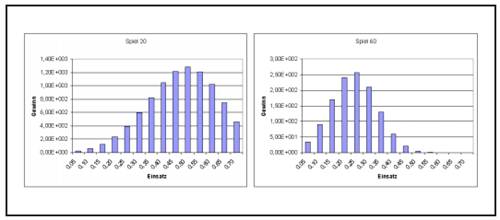
Abbildung 2.1: Das Münzwurf-Spiel nach 20 und 60 Münzwürfen
2.3.3 Position Sizing
Der Erfolg beim Agieren am Finanzmarkt hängt entscheidend von der Größe der einzugehenden Position ab. Wie diese Größe bestimmt werden kann, wird im Folgenden dargelegt. In Anlehnung an Tharp in (Tha99, Kapitel 12) wird hier von „Positionsgrößenbestimmung" bzw. „Position Sizing" gesprochen, da die alternative Bezeichnung „Money Management" in der Literatur mit wechselnden Bedeutungen belegt ist.
Diese Einführung orientiert sich an (Vin95, Kapitel 1, 2). Dort beschreibt Vince eine Methode, den optimalen Anteil am vorhandenen Kapital zu bestimmen, der jeweils in die existierenden Anlagemöglichkeiten investiert werden sollte, um das optimale Chance/Risiko-Verhältnis zu erhalten.
Um zu veranschaulichen, wie wichtig es ist, den optimalen Anteil am vorhandenen Kapital in eine Anlage zu investieren, führt Vince in (Vin95, S. 14) ein Münzwurf-Spiel vor. Im Verlustfall ist der Einsatz verloren, ansonsten gewinnt der Spieler das Doppelte des eingesetzten Kapitals. Der Erwartungswert dieses Spieles ist 0,5, d.h. im arithmetischen Mittel gewinnt der Spieler bei jedem Spiel die Hälfte seines Einsatzes dazu. Ausgehend von einem gewissen Startkapital ist zu entscheiden, welcher Anteil des Kapitals bei jedem Spiel einzusetzen ist, um das maximale Endkapital bei optimalem Chance-/Risiko- Verhältnis nach einer großen aber endlichen Anzahl von Spielen zu erzielen. Das Ergebnis einer Reihe solcher Spiele nach verschieden vielen Münzwürfen ist in Abbildung 2.1 und Abbildung 2.2 auf der nächsten Seite dargestellt.
Es werden 14 Strategien verglichen, die jeweils einen anderen aber festen Anteil des jeweils verfügbaren Kapitals bei jedem einzelnen Spiel eingesetzt haben. Der erste Spieler setzt stets 0,05 seines Kapitels ein, der zweite 0,1 und so fort bis zum 14. Spieler, der bei jedem Spiel 0,7 seines Kapitals riskiert. In den Balkengrafiken sind die Spieler mit steigender Risikofreudigkeit auf der Abszisse von links nach rechts eingetragen, auf der Ordinate das jeweilige Kapital des Spielers zu dem jeweiligen Zeitpunkt des Spiels. Nach Spiel Nr. 20 liegt
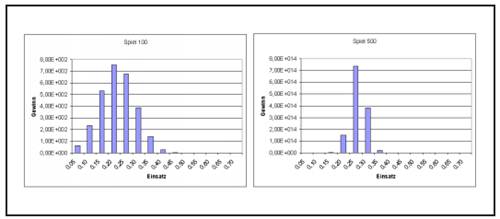
Abbildung 2.2: Das Münzwurf-Spiel nach 100 und 500 Münzwürfen
der Spieler, der immer 0,5 seines Kapitals einsetzt, vorne. Jedoch verschiebt sich der optimal einzusetzende Kapitalanteil mit dem weiter laufenden Spiel immer weiter hin zur Risikoärmeren Haltung, bis sich 0,25 des eingesetzten Kapitals als der optimale Einsatz ergeben. Dies ist je nach Spielverlauf zwischen Spiel 200 und 500 der Fall, evtl. auch schon früher.
In Abbildung 2.2 rechts ist deutlich zu erkennen, dass sich die Unterschiede beim Endkapital mit zunehmender Länge des Spieles verstärken. Schon wenige Prozent Abweichung vom optimal einzusetzenden Anteil ergeben einen signifikanten Nachteil. Dabei ist eine Abweichung zu niedrigerem Risiko gegenüber einem höheren Risiko deutlich vorzuziehen. Es ist in der Grafik zum 500. Spiel zwar nicht zu erkennen, aber die Spieler, die 0,05-0,15 eingesetzt haben, haben einen gewissen Gewinn erzielt. Diejenigen Spieler, die 0,5 und mehr pro Spiel einsetzten, haben ihr gesamtes Kapital verloren.
Wie deutlich geworden ist, existiert für das Münzwurfspiel ein optimal einzusetzender Anteil des zur Verfügung stehenden Kapitals. Vince nennt diesen Kapitalanteil „Optimal f", wobei f für „fraction" (engl. Bruchteil) steht. In (Vin95, S. 27) wird ausgeführt, dass bei einem Spiel wie dem oben beschriebenen, welches zu jedem Zeitpunkt nur zwei mögliche Ausgänge hat, sich das Optimal f berechnen lässt nach f = ]=. Dabei ist E der Erwartungswert des Spiels und b das Verhältnis von Gewinn zu Verlust. Für das obige Beispiel ergibt sich mit E = 0,5 und b = j demnach: f = %^ = 0,25.
Laut (Vin95, S. 16) existiert ein optimaler einzusetzender Kapitalanteil für jede Investition, die einen positiven Erwartungswert aufweist. Im Gegensatz zu dem oben dargestellten Spiel ist Optimal f von Handelssystemen und sonstigen Investitionen nicht stationär (vgl. (Vin95, S. 22)). Aufgrund der Dynamik des Marktes ist eine ständige Überprüfung des Optimal f nötig. Um sicherzustellen, dass die verwendete Positionsgröße noch stimmt, ist eine regelmäßige Überprüfung im Laufe der Handelstätigkeit unerlässlich.
Liegt eine Verteilung von Erträgen mit ihren Eintrittswahrscheinlichkeiten vor, wie es bei einem Handelssystem durch die Historie gegeben ist, gelten nach (Vin95, S. 44f) die im Folgenden dargestellten Zusammenhänge. Hierbei wird davon ausgegangen, dass alle Erträge mit einer festen Anzahl von Wertpapieren erzielt wurden bzw. die Ergebnisse auf eine solche feste Anzahl normalisiert wurden. Diese Anzahl an Wertpapieren wird als eine Einheit betrachtet und es wird berechnet, wie viele solcher Einheiten optimalerweise hätten gehandelt werden sollen. Unter der Annahme, dass die zukünftige Handelsaktivität ähnlich verläuft wie die historische, kann die so ermittelte Positionsgröße für den zukünftigen Handel verwendet werden.
Für die einzelnen Halteperioden werden die prozentualen Erträge relativ zum riskierten Kapital ermittelt. Dies bezeichnet Vince als HPR („holding period return"), den relativen Ertrag einer Halteperiode.
Als Maß für das Ertrag/Risiko-Verhältnis einer einzelnen Halteperiode bestimmt Vince das Verhältnis vom Ertrag der betrachteten Periode und dem absoluten maximalen Verlust aller Perioden. Multipliziert man dies mit dem eingesetzten Anteil des Kapitals, erhält man die relative Änderung des Kapitals durch diese Handelsaktivität

mit Ai als dem Ertrag der Halteperiode i, L als dem größten einzelnen Verlust aller Halteperioden und f als dem eingesetzten Kapitalanteil.
Der relative Endwert zum Anfangskapital nach T Haltedauern ist definiert durch:

wobei TWR für „terminal wealth relative" steht. Der geometrisch durchschnittliche Ertrag einer Halteperiode ist gegeben durch:

Das Optimal f, das während jeder Haltedauer investiert werden sollte, ergibt sich, indem G bzw. TWR maximiert wird.
Mit

ergibt sich das Kapital, für das jeweils eine Einheit des Wertpapiers gehandelt werden sollte. Dabei ist L der größte aufgetretene Verlust einer einzelnen Handelsaktivität, der in der Vergangenheit aufgetreten ist.
Das genannte Vorgehen wird nun anhand eines Beispiels verdeutlicht: Es sei die Folge von Erträgen eines Handelssystems durch (+2,-3,+10,-5) gegeben, die mit einer Einheit eines Wertpapiers erzielt worden sind. Indem f in kleinen Schritten bei 0 beginnend erhöht wird, ergibt sich ein maximales TWR von 1,0163 bzw. ein maximales G von 1,004 bei f = 0,17. Es ergibt sich f$ = abQs^5' = 29,41. Dies bedeutet, mit einem Kapitaleinsatz von jeweils 29,41 wird eine Einheit des Wertpapiers bei der zukünftigen Handelsaktivität gehalten. Bei einem angenommenen Gesamtkapital von 1000 entspricht dies = 34 Einheiten des Wertpapiers. Da unbedingt zu vermeiden ist, ein höheres als das optimale Risiko einzugehen, wird die Anzahl der Einheiten immer abgerundet. Um möglichst nah am Optimal f zu sein, sollte die Größe der Wertpapiereinheit so klein wie möglich gewählt werden. Dies stellt laut (Vin92, S. 83) den optimal zu investierenden Anteil des Kapitals dar.
Das Optimal f lässt sich auch für die Komponenten eines Portfolios berechnen und wird z.B. von Vince in (Vin90, S. 162) oder (Vin95, S. 40) diskutiert. Da sich diese Arbeit auf den Handel mit einem einzelnen Wertpapier beschränkt, wird dies hier nicht näher betrachtet.
Drawdown Unter einem Drawdown versteht man den Verlust durch mehrere Handelsaktivitäten, der innerhalb der Kapitalkurve eines Handelssystems auftritt, bis wieder ein neuer Höchststand erreicht wird. Viele Autoren halten den maximalen Drawdown eines Handelssystems für wesentlich, z.B. Arndt in (AB05, S. 37f) und bevorzugen Handelssysteme mit geringen Drawdowns. Tatsächlich entzieht sich der Drawdown jedoch völlig der Kontrolle des Entwicklers eines Handelssystems (vgl. (Vin90, S. 105)). Vince argumentiert, dass die Ausgänge der einzelnen Handelsaktivitäten unabhängige zufällige Ereignisse darstellen. Wäre dies nicht der Fall, müsste man diese Abhängigkeiten innerhalb der Folge der Handelsaktivitäten nutzen, um das Handelssystem zu verbessern, bis die Handelsaktivitäten unabhängige zufällige Ereignisse darstellen. Daher ist der Drawdown eines Handelssystems bedeutungslos, wohingegen der maximale Verlust, der durch eine einzelne Handelsaktivität auftreten kann, wesentlich und beeinflussbar ist.
Es ist möglich, dass alle oder viele Verluste einer betrachteten Periode direkt nacheinander auftreten. Obwohl die Kapitalkurve nach einem solchen Drawdown den Eindruck vermitteln kann, das System funktioniere nicht oder nicht mehr, kann es sich bei dieser Häufung um Zufall handeln. Je länger ein Handelssystem am Markt agiert, umso höher ist die Wahrscheinlichkeit, dass sich ein großer Drawdown ereignet. Wie Vince in (Vin90, S. 105) hinweist, folgt hieraus das Paradoxon, dass besonders gute Handelssysteme, die daher ein großes Optimal f aufweisen und diesen Kapitalanteil tatsächlich riskieren, auch besonders große Drawdowns aufweisen. Wie in (Vin90, S. 169) hingewiesen wird, kann man durch das Riskieren von weniger als dem optimalen Kapitalanteil die Drawdowns zwar arithmetisch senken, jedoch wird dadurch das erzielbare Endkapital geometrisch verringert.
Unter dem maximalen Drawdown versteht man den größten Drawdown in der Kapitalkurve. Vince schlägt vor, nach einem neu aufgetretenen maximalen Drawdown den Handel des Handelssystems so lange nur noch simuliert fortzuführen, bis seine Kapitalkurve ein neues Allzeithoch erreicht hat, um sicher zu gehen, dass das System noch funktioniert.
2.3.4 Vergleich von Handelssystemen
Um Kapitalanlagen zu vergleichen, werden in der Literatur verschiedene Kennzahlen vorgeschlagen (vgl. (WS99a, S. 250-254), (WS99b, S. 308-315)). Ge-
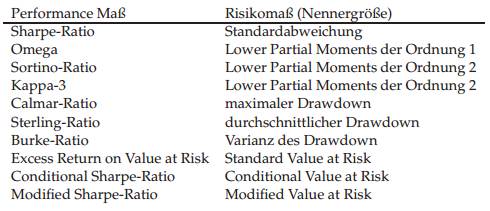
Tabelle 2.1: Übersicht verschiedener gebräuchlicher Performance-Maße mit ihren zugehörigen Risiko-Maßen. Im Zähler des Performance-Maßes steht jeweils die Überrendite über der risikolosen Anlage.
wöhnlich wird die durchschnittliche Überrendite der Anlage gegenüber einer risikolosen Anlage im Verhältnis zum eingegangenen Risiko betrachtet. Diese risikoadjustierten Performance-Maße unterscheiden sich daher im Wesentlichen im zugrunde gelegten Risiko-Maß. In der Tabelle 2.1 sind drei verschiedene Kategorien von Performance-Maßen zu unterscheiden: Sharpe-Ratio, Omega-Ratio, Sortino-Ratio und Kappa-3 basieren auf Risiko-Maßen, die mithilfe der (angenommenen) Normal-Verteilung der Renditen bestimmt werden. Calmar-Ratio, Sterling-Ratio und Burke-Ratio basieren auf dem Drawdown der Anlage. Excess Return on Value at Risk, Conditional Sharpe-Ratio sowie Modified Sharpe-Ratio basieren auf dem Value at Risk. Der Wert im Risiko (Value at Risk, VaR) gibt an, welchen Wert der Verlust einer bestimmten Risikoposition mit einer gegebenen Wahrscheinlichkeit und in einem gegebenen Zeithorizont nicht überschreitet.
Vince schlägt in (Vin95, S. 188) das „growth risk ratio"

vor mit TWR als dem relativen Maß für das Kapital-Wachstum des Handelssystems und f als dem riskierten Anteil des Kapitals. Dieses Maß ähnelt sehr dem Excess Return on Value at Risk aus Tabelle 2.1.
Handelssysteme, deren jeweils riskierter Kapitalanteil nicht bekannt ist, sollten dennoch unabhängig vom jeweils verwendeten Hebel verglichen werden. Dazu ist es notwendig, die Ergebnisse auf den gleichen Hebel zu normalisieren. Vince schlägt in (Vin90, S. 80f) vor, die Handelssysteme auf den optimalen f-Wert des Systems mit dem kleinsten Optimal f zu normalisieren und das System zu bevorzugen, das bei diesem f-Wert den höchsten Geometrischen Mittelwert G aufweist.
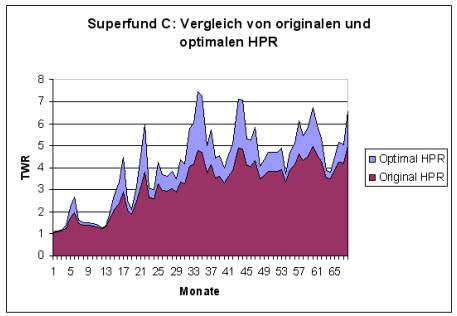
In den Abbildungen 2.3, 2.4 und 2.5 ist exemplarisch ein grafischer Vergleich von dem Handelssystem „Superfund" dargestellt, das in drei Varianten A,B und C mit steigendem Hebel verfügbar ist. Es sind jeweils die kumulierten
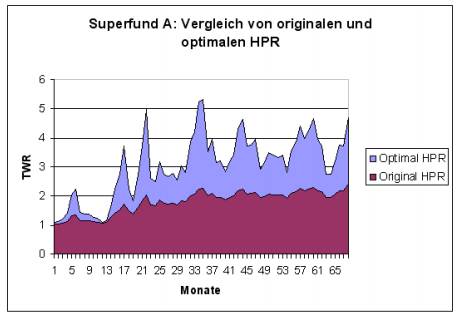
monatlichen HPR des originalen und der theoretischen, auf Optimal f optimierten Variante des Handelssystems aufgetragen. Die Daten für diese Beispiele sind der öffentlichen Webseite des Fondsmanagers dieser Produkte entnommen (vgl. (Sup)). Es handelt sich bei „Superfund" um ein systematisches Handelssystem aus dem Bereich der „Managed Futures".
Wie man auf Abbildung 2.3 und Abbildung 2.4 erkennt, sind „Superfund A" und „Superfund B" relativ weit vom optimalen Kapitaleinsatz entfernt. Die optimalen und originalen f-Werte und TWR sind der Tabelle 2.2 auf der nächsten Seite zu entnehmen. „Superfund A" wird mit einem f-Wert von 0,167 gehandelt, wobei das Optimal f bei 0,48 liegt. „Superfund B" hat den f-Wert 0,23, wobei 0,46 optimal wäre. Der in Abbildung 2.5 auf Seite 31 dargestellte „Superfund C" vollzieht die optimale Kapitalkurve schon wesentlich besser nach. Trotzdem ist er mit einem f-Wert von 0,31 vom optimalen f von 0,49 noch relativ weit entfernt. Die optimalen f-Werte aller drei Fonds liegen mit 0,46 bis 0,49 in ungefähr dem gleichen Bereich. Daher kann vermutet werden, dass es sich um annähernd das gleiche unterliegende Handelssystem handelt, das jeweils mit unterschiedlichen Hebeln arbeitet.
Die Bestimmung des Optimal f aufgrund von monatlichen HPR, wie im obigem Beispiel vorgenommen, ist problematisch. Zwischenzeitliche Verluste durch einzelne Transaktionen könnten im weiteren Verlauf des Monats durch Gewinne verschleiert werden. Da für die Bestimmung des Optimal f der maximale Verlust einer einzelnen Transaktion wesentlich ist, wird so das Risiko eines Handelssystems evtl. unterschätzt. Daher ist durchaus möglich, dass „Superfund C" den optimalen Kapitalanteil riskiert. Ohne Kenntnis der ein-
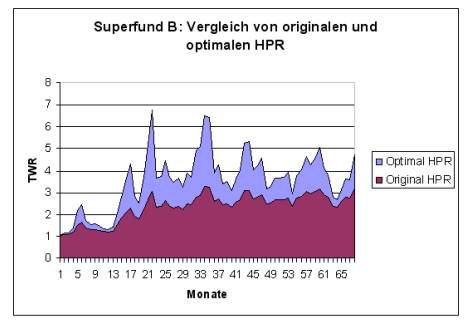

Tabelle 2.2: Vergleich von Superfund A,B und C hinsichtlich ihrer TWR bei originalen und optimalen f-Werten
zelnen Transaktionen ist dies schwer zu entscheiden.
Eine wesentliche Gefahr bei der Bestimmung des Optimal f besteht darin, dass die zugrunde gelegte Handelshistorie den maximalen Einzelverlust, der für das Handelssystem charakteristisch ist, nicht enthält. Eine Möglichkeit, diesem Problem zu begegnen, ist, zur Bestimmung des Optimal f statt des historischen maximalen Einzelverlustes den für den Anwender maximal erträglichen Verlust zur Berechnung des f-Wertes heranzuziehen. Da dieser größer gewählt werden muss als der historische maximale Einzelverlust, wird der bestimmte f-Wert kleiner. Dieser kleinere riskierte Kapitalanteil wird auch als „Secure f" bezeichnet (vgl. (Lor05, S. 133-145)).
2.3.5 Fundamentale versus Technische Analyse
Eine Alternative zur Technischen Analyse stellt die Fundamentale Analyse dar. Bei dieser wird versucht, den „inneren Wert" eines Wertpapiers mit Me-
thoden zu ermitteln, welche auf die Bewertung des Ertrages oder Substanzwertes der zugrunde liegenden Wirtschaftseinheit abzielen, siehe (Wel94, S. 17-21). Weicht dieser ermittelte Werte vom aktuellen Kurswert ab, veranlasst dies fundamental orientierte Anleger zu Käufen oder Verkäufen des Wertpapiers. Je nachdem, welches Verfahren der Anleger wählt, um den „inneren Wert" eines Unternehmens zu bestimmen, muss er einige Unternehmensdaten zur Verfügung haben, die ihn unter Umständen mit Zeitverzögerung erreichen. Zudem muss er einige Daten schätzen, wie z.B. Liquidationserlöse, zukünftige Erträge oder zukünftige Zinssätze. Um eventuelle Ungenauigkeiten zu berücksichtigen, kann der Anleger statt expliziter Werte jeweils Wertebereiche zugrunde legen. Dadurch ergibt sich bei dem ermittelten „inneren Wert" ebenfalls ein Wertebereich. Je nach Genauigkeit der Schätzungen kann der ermittelte Wertebereich des „inneren Wertes" Ausmaße annehmen, die kein profitables Handeln ermöglichen.
Aufgrund dieser Schwierigkeiten bei der Bestimmung des „inneren Wertes" eines Wertpapiers mittels der Fundamentalen Analyse verwenden viele Anleger die Technische Analyse zumindest zusätzlich. Dabei wird mit kürzerem Zeithorizont der Anlage die Wichtigkeit der Technischen Analyse immer größer und die der Fundamentalen Analyse kleiner: Fundamentale Faktoren ändern sich auf kleinen Zeithorizonten nicht, während durchaus Kursänderungen festzustellen sind.
Die Technische Analyse verwendet ausschließlich historische Kursdaten für die Analyse eines Wertpapiers. Es wird davon ausgegangen, dass der Kurs nicht verzögerungsfrei und vollständig auf Änderungen der fundamentalen Daten reagiert, sondern im Kursverlauf eine Änderung der Einschätzung eines Teils der Marktteilnehmer frühzeitig sichtbar wird und der Kurs eine gewisse Zeit benötigt, bis er sein neues Niveau gefunden hat. Welcker identifiziert in (Wel94, S. 21-24) Gründe, warum die Technische Analyse der Fundamentalen Analyse überlegen sein kann:
Informationsvorsprung ist unwahrscheinlich: Sofern der Anleger kein Insider ist, ist es unwahrscheinlich, dass er den Wert besser einschätzt als die anderen Marktteilnehmer.
Die Aktionen der besser informierten Insider werden im Kursverlauf sichtbar, lange bevor die Information öffentlich wird.
Kurse sind von Einschätzungen anderer abhängig: Selbst wenn der fundamentale Anleger mit seiner Einschätzung recht hat, kann er Verluste erleiden, weil ein großer Teil der Marktteilnehmer ein Wertpapier anders bewertet.
Effizienter Markt Hypothese Nach der Effizienten Markt Hypothese (EMH) ist ein Markt effizient, wenn alle verfügbaren Informationen in den Preisen enthalten sind (vgl. (EFF72, S. 335f)). Eugene Fama unterscheidet zwischen der schwachen, semi-starken und starken Form der Effizienz eines Marktes. Im Falle der schwachen Effizienz eines Marktes kann man aus historischen Kursen keine Informationen gewinnen, die nicht schon in diesen Preisen enthalten wären. Ist ein Markt semi-stark effizient, ändern sich die Preise in so kurzer Zeit und unvorhersagbar aufgrund neuer öffentlich bekannter Informationen, dass kein Überschuss-Gewinn erzielbar ist. Ein Markt wird stark effizient genannt, wenn nicht einmal durch wichtige Informationen, die nur einzelnen oder Gruppen von Investoren bekannt sind, Überschussgewinne erzielt werden können. Viele Ökonomen gehen davon aus, dass zumindest die schwache Form der Markteffizienz auf den Märkten gegeben ist (RG01, S. 349). Demnach könnte kein Handelssystem, das nur mit historischen Kursen arbeitet, bei gleichem Risiko eine höhere als die Marktrendite erwirtschaften. Es gibt jedoch Hinweise darauf, dass Preis-Bewegungen innerhalb der Finanzmärkte im kurz- bis mittelfristigen Zeitrahmen zu einem gewissen Grade vorhersagbar sind. Insbesondere hat die Forschung auf dem Gebiet der Entwicklung von Handels- und Vorhersagesystemen für die Finanzmärkte mithilfe der Methoden der künstlichen Intelligenz im Laufe der letzten Jahrzehnte stark zugenommen. Trotzdem ist die Anzahl derjenigen Publikationen, die detailliert über die von ihnen entwickelten Systeme berichten, sehr gering. Clarence vermutet in (DCNWT99, S. 4), dies rühre teilweise daher, dass der starke Wettbewerb zwischen Handelshäusern, marginale Verbesserungen der eigenen Handelsstrategien zu erzielen, die sich in erhebliche Gewinne umsetzen lassen, sie unwillig gegenüber dem Publizieren der Methoden ihrer Handelssysteme werden lässt. Eigene Erfahrungen in der Erstellung von Handelssystemen zeigen jedoch, dass schon geringe Abweichungen etwa durch Implementationsunterschiede massive Auswirkungen auf das Handelsverhalten haben können. Daher ist kaum damit zu rechnen, dass ein System unbrauchbar wird, wenn man es publiziert. Im Sinne der selbsterfüllenden Prophezeiung wäre es sogar denkbar, dass ein System davon profitiert, wenn es von einer größeren Anzahl Marktteilnehmer angewandt wird. Manche Autoren gehen sogar davon aus, dass die technische Analyse nur deshalb funktioniert, weil sie von vielen Marktteilnehmern angewandt wird.
Lo schlägt in (Lo04) eine Alternative zur umstrittenen EMH vor: die „adaptive market hypothesis" (AMH). Hierbei handelt es sich um eine Sichtweise des Markes der obwohl von Gier und Furcht der einzelnen Marktteilnehmer getrieben, dennoch eine Form von Effizienz inne hat. Die Kurs-Bewegungen werden dabei zurückgeführt auf Anpassungs- und Selektions-Effekte der Marktteilnehmer, wobei sich die Marktteilnehmer quasi evolutionär entwickeln und den geänderten Gegebenheiten anpassen. Aus dieser neuen Sicht auf den Markt als einen evolutionären, sich anpassenden Prozess folgt, dass ein Handelssystem, das erfolgreich sein soll, imstande sein muss, sich an die sich ändernden Marktbedingungen anzupassen. Im Gegensatz zur EMH sieht Lo in (Lo04, S. 22) durchaus die Möglichkeit für Arbitrage in der AMH. Dabei folgt er Grossmann und Stieglitz (GS80, S. 393-408), die argumentieren, dass es ohne Profitgelegenheiten keinen Anreiz zur Informationbeschaffung am Kapitalmarkt gäbe und daher der Handel zum Erliegen kommen würde. Aus evolutionärer Sicht folgt aus der Existenz von liquiden Märkten, daß Profitmöglichkeiten vorhanden sein müssen.
Annahmen über den Entstehungsprozess der Zeitreihe Um ein Handelssystem zu entwickeln, das durch Timing-Entscheidungen profitabel arbeitet, ist es notwendig, Prognosen über die zukünftige Entwicklung der PreisZeitreihe zu machen. Eisenbach definiert in (Eis05, S. 16) eine Prognose als „die Vorhersage zukünftiger Ereignisse auf Grund von Vergangenheitsinformation". Es ist also Voraussetzung, dass nicht alle Vergangenheitsinformationen im aktuellen Kurs enthalten sind. Dies könnte man so erklären, dass es zu jedem Zeitpunkt agierende und beobachtende Marktteilnehmer gibt. Bei den agierenden Martteilnehmern kam es im betrachteten Zeitraum zu Vertragsabschlüssen, während die Beobachter diese Aktionen registrierten, verarbeiteten und in zukünftigen Zeitpunkten darauf reagierten. Die aktuellen Preise reflektieren daher nicht die Einschätzung des gesamten Marktes, sondern nur die der Agierenden. Bis der Preis die Einschätzungen des gesamten Marktes widerspiegelt, müssen die Beobachter Gelegenheit gehabt haben, zu agieren. Diese Zeitspanne hängt von der Verbreitungsgeschwindigkeit der Informationen im Markt, der Verarbeitungszeit dieser Information durch die Beobachter, der Frequenz der Beobachtung sowie der Ausführungsgeschwindigkeit der Order ab. Da die Informationsverbreitungsgeschwindigkeit und die Ordererteilungs- und Ausführungsgeschwindigkeit heutzutage im Sekundenbereich liegen, fallen diese Zeitspannen nicht weiter ins Gewicht. Wesentlich dürfte die Zeit zur Informationsverarbeitung und die Beobachtungsfrequenz sein. Noch immer wird ein Großteil der Investitionsentscheidungen von Menschen getroffen, deren Frequenz für die Kenntnisnahme von Marktinformationen eher in Stunden oder Tagen zu messen ist als in Sekunden. Darüber hinaus werden immer nur Teilbereiche der theoretisch verfügbaren Marktinformationen zur Entscheidungsfindung herangezogen. Außerdem unterliegen Menschen Emotionen, was wahrscheinlich ihr Verhalten am Markt beeinflusst. Die Folgerung, dass in einem effizienten Markt kein Überschussgewinn mit Handelssystemen erzielt werden kann, basiert auf der Annahme, dass alle Investoren homogen nach dem rationalen Erwartungsmodell handeln (EFF72, S. 335). Gencay weist in (RG01, S. 349-355) darauf hin, dass, wenn diese Annahme falsch ist, auch die Folgerung, dass Vorhersagen unmöglich sind, zumindest fraglich ist. Laut Gencay steigt das Interesse von Spezialisten an der Idee von der heterogenen Erwartungshaltung der Marktteilnehmer (vgl. (RG01, S. 350ff)). Den experimentellen Ergebnissen von Dodonova und Khoroshilov (vgl. (DK07, S. 5)) zufolge investieren die meisten Marktteilnehmer nicht nach dem rationalen Erwartungsmodell, sondern nach Trends und Mode. Eine mit der Zeit veränderliche Erwartungshaltung der Marktteilnehmer hält Gencay für realistischer als das Modell der rationalen Erwartung der Marktteilnehmer.
2.3.6 Der Währungsmarkt
Im Rahmen der Entwicklung eines Handelssystems besteht eine wesentliche Entscheidung darin, den Markt festzulegen, in dem das Handelssystem arbeiten wird. Der Währungsmarkt hat eine Reihe von Eigenschaften, die ihn für die Entwicklung von Handelssystemen besonders interessant machen.
Laut (RG01, S. 13f) ist der Währungsmarkt der Markt mit den größten täglichen Umsätzen. Aufgrund der hohen Liquidität können qualitativ hochwertige Daten von diesem Markt gewonnen werden. Insbesondere der EUR/USD- Markt, einer der größten Währungsmärkte überhaupt, ist aufgrund der hohen Qualität der gewonnenen Kursinformationen Gegenstand vieler Untersuchungen. Im Gegensatz zu Aktienmärkten gibt es für die Währungsmärkte keine bekannte „Kaufen und Halten" Strategie. Wer am Währungsmarkt Gewinne erwirtschaften möchte, ist daher auf ein Handelssystem angewiesen. Im Gegensatz zu kleineren Märkten wie z.B. einzelnen Aktien ist der Währungsmarkt aufgrund seiner Größe vor Kursmanipulation durch einzelne Investoren weitgehend geschützt. Ein weiterer Vorteil besteht darin, dass die möglichen Positionsgrößen sehr gut skalierbar sind. Sowohl sehr kleine als auch sehr große Positionen können mit geringen Transaktionskosten eingegangen werden.
Währungshandel Sofern man über keinen direkten Zugang zu einem Währungsmarkt verfügt, benötigt man einen Broker, der die entsprechende Zulassung besitzt und die Abwicklung der Orders übernimmt. Es wird zwischen Market Makern und ECN (Electronic Communication Network) Brokern unterschieden. Market Maker verlangen in der Regel keine Ordergebühren und bieten eine relativ konstante Differenz zwischen Kauf- und Verkauspreis (Spread) an, der nur in Zeiten hoher Volatilität ausgeweitet wird. ECN Broker bieten direkten Zugang zu einem oder mehreren Märkten an und berechnen pro Order eine Gebühr. Der Spread variiert je nach Markt und kann im Extrem sogar wegfallen. Da die meisten Broker im Währungsbereich Market Maker sind, wird im Folgenden von einem Market Maker als Broker ausgegangen. Durch die Verwendung eines ECN Brokers wären vermutlich etwas günstigere Ausführungen möglich. Allerdings stehen die zur Abschätzung des Spread notwendigen Daten nicht zur Verfügung.
Der Spread beträgt je nach Broker zwischen 1 und 3 Pips im EUR/USD (Euro/US Dollar Wechselkurs) während der Haupthandelszeit bei normalen Kursschwankungen. Als Pip bezeichnet man die kleinste Änderungseinheit einer Währung. Beim EUR/USD Wechselkurs etwa entspricht ein Pip 0,0001 Euro.
2.3.7 Entwicklungsansätze für Handelssysteme in der Literatur
Die Ansätze zur Entwicklung von Handels- bzw. Prognosesystemen, die sich in der Literatur finden, sind vielfältig. Hier werden zunächst verschiedene ausgewählte Anwendungsbeispiele betrachtet und im nächsten Kapitel die Möglichkeiten zur Entwicklung eines Handelssystems mittels evolutionärer Verfahren besprochen.
In (GBD+00, S. 13f) beschreiben Gencay et al. ihre Herangehensweise zur Erstellung eines Handelssystems für Währungen. Das Handelssystem erzeugt mithilfe spezieller gleitender Durchschnitte pro Woche im Durchschnitt ein Kaufsignal. Als Datengrundlage für die Simulation dienen die Wechselkurse von USD/DEM, USD/CHF, USD/FRF sowie USD/JPY auf 5-Minuten Basis. Gencay et al. kommen zu dem Schluss, dass im betrachteten Zeitraum 1989 bis 1996 mithilfe seines Handelssystems annualisierte Renditen zwischen 3.66% bei USD/CHF und 9,63% bei USD/DEM erzielt werden konnten. Im Vergleich zum Parker Systematic Index, der annualisiert eine Rendite von 10,76% ausweist, kann das Handelssystem von Gencay eine annualisierte Rendite von 12,65% nach branchenüblichen Verwaltungsgebühren vorweisen. Der Unterschied zu den vorher genannten Renditen ergibt sich durch die Zusammenstellung des Portfolios und der zur Vergleichbarkeit verwendeten Hebel. Neely et al. verwenden in (NWD97, S. 9-15) GP, um technische Handelsregeln zu entwickeln. Sie finden starke Hinweise auf ökonomisch signifikante out- of-sample Überrenditen dieser Handelsregeln für jede der sechs untersuchten Währungspaare während der Periode von 1981 bis 1995.
Levich beschäftigt sich in (RML91,10-15) mit der Signifikanz der mittels technischer Handelsregeln erzielten Profite im Währungsmarkt. Er versucht die Signifikanz der verwendeten Handelsregeln zu zeigen, indem er das sogenannte "Bootstrap"Verfahren anwendet. Hierzu werden neue Zeitreihen erstellt, indem Permutationen der Preisänderungen der ursprünglichen Zeitreihe gebildet werden. Auf diese Zeitreihen werden die Handelsregeln angewendet, um zu sehen, ob ähnliche Resultate wie mit den ursprünglichen Zeitreihen erzielbar sind. Dies ist nicht der Fall, Levich kommt zu dem Schluss, dass die ursprünglichen Kursverläufe nicht seriell unabhängig sind und Informationen enthalten müssen, welche durch die verwendeten einfachen Handelsregeln auf Basis gleitender Durchschnitte ausnutzbar sind. Diese Informationen gehen bei der Permutation der Zeitreihe verloren.
Zschischang berichtet in (Zsc05, S. 14-16) von einem auf Fuzzy-Regeln basierendem Handelsprogramm für kurzfristige Anleihen, das die japanische Fuji- Bank 1990 in ihr Tagesgeschäft eingebunden hat. Mittels eines Regelsatzes gibt das Handelssystem Empfehlungen, die sich als profitabel herausstellten. Da profitable Regeln im Laufe der Zeit vom Markt absorbiert werden, waren die Händler gezwungen, die Regeln zu ändern, wobei sie vom System durch Backtesting unterstützt wurden.
- Arbeit zitieren
- Holger Hartmann (Autor:in), 2007, Entwicklung von Handelssystemen mittels Genetischer Programmierung anhand eines Fallbeispiels, München, GRIN Verlag, https://www.grin.com/document/186383

Ähnliche Arbeiten



















Kostenlos Autor werden


Kommentare