Leseprobe
Fachhochschule Darmstadt
![]()
Entwicklung eines
verteilten Kundeninformationssystems
Band II - Applikationsserver und Wrapping von Legacy-Systemen
Darmstadt, im März 2000
Eidesstattliche Erklärung
Danksagung
Vorwort
XV
Einleitung
1 Einleitung
Das erste Kapitel der Arbeit erklärt das zu bearbeitende Thema und die Auf- Es wird aufgezeigt, was die Diplomarbeit leisten sollte und warum sie durchgeführt wurde.
1.1 Aufgabenstellung
Die praktische Aufgabenstellung kam aus dem Geschäftsbetrieb der Firma Samsung Semiconductor Europe.
Samsung Semiconductor Europe vertreibt die in Korea hergestellten Halbleiterprodukte und TFT-Panels für den europäischen Markt. Das Kundenspektrum reicht von Großkonzernen wie IBM, DELL, Hewlett Packard, Nokia und Siemens, über Wiederverkäufer bis hin zu kleinen Computerläden. Während des Vertriebsprozesses fallen eine Vielzahl von Informationen und Daten an, die im SAP R/3 System von Samsung gespeichert sind. Am Anfang des Prozesses steht die Bestellung, daraus ergibt sich die Lieferung und endet
in der Rechnungsstellung.
Möchte ein Kunde sich einen Überblick über diese Daten verschaffen, so kontaktiert er Samsung telefonisch, per Fax oder Email. Diese Vorgehensweise ist jedoch nicht nur fehleranfällig, weil man sich beispielsweise missverstehen kann oder das Fax schlecht zu lesen ist. Weiterhin bindet es teure Arbeitszeit eines Mitarbeiters bei Samsung.
Die Idee von Samsung war es, ein Kundeninformationssystem zu schaffen. Die benötigten Informationen können so über das Internet dem Kunden zur Verfügung gestellt werden. Dieser kann in einem Self-Service-Szenario seine Daten jederzeit und immer aktuell einsehen.
Als weiteres Einsatzgebiet sollte das Kundeninformationssystem dazu genutzt werden, eine Reklamation über das Internet anzustoßen.
1.2 Anforderungen
Das Kundeninformationssystem musste in einer mehrschichtigen Anwendungsarchitektur entwickelt werden, da zum einen die Schnittstelle mit den Benutzern
Einleitung
ein Webbrowser war. Zum anderen stellte die Datenquelle des
Kundeninformationssystems das SAP R/3 System dar, welches in das neue System eingebunden werden musste.
In der mittleren Schicht des Systems führten Komponenten die Anwendungslogik aus. Wobei die Komponenten einen Applikationsserver als Ausführungsumgebung verwandten.
Somit wurde das Kundeninformationssystem unter den neuesten Erkenntnissen und Paradigmen der Informatik erstellt. Hierbei war die objektorientierte Programmierung ebenso obligatorisch, wie das beim Entwicklungsprozess eingesetzte Prototyping-Modell.
Um einzelne Produkte und Technologien einschätzen und bewerten zu können, wurde das Anwendungssystem durch zwei Technologiestränge realisiert. Ein Lösungsweg wurde durch den Einsatz von Microsoft Produkten realisiert. Der andere wurde auf der Basis von Javatechnologien, der Java 2 Enterprise Edition (J2EE), erstellt.
Hier wurde insbesondere der Microsoft Transaction Server dem Gemstone/J Applikationsserver gegenübergestellt.
1.3 Ziele
Im theoretischen Teil der Arbeit beschäftigte ich mich mit Microsofts Komponentenarchitektur „Component Object Model“ (COM), Applikationsservern und Wrapping von Legacy-Systemen.
Hierbei sollte ein Einblick in Microsofts „Component Object Model“ gegeben werden. Weiterhin untersuchte ich die Interoperabilität zwischen C++ und Visual
Basic bei der COM-Programmierung. Im Rahmen der Arbeit sollten die
Möglichkeiten und Unterschiede von Applikationsservern der Enterprise JavaBean Architektur und dem Applikationsserver Microsoft Transaction Server untersucht werden.
Der praktische Teil bestand in der Realisierung des Kundeninformationssystems. Dabei wurde die praktische Arbeit in zwei Hälften geteilt. Der Kommilitone Herr Ebers übernahm hierbei den Frontendbereich bis hin zur mittleren Schicht. In den Aufgabenbereich von Herrn Ebers fiel die Erstellung der Schnittstellen mit den Benutzern, den Webseiten. Meine Aufgabe war es,
Einleitung
die Anbindung an das SAP R/3 System zu realisieren. Aufgaben im Bereich der Applikationsserver teilten wir zwischen uns auf. Weiterhin gehörte die Erstellung eines Administrations-Frontends in meinen Aufgabenbereich.
1.4 Motivation
Aus meiner Sicht bot mir diese Arbeit die Chance, mein Wissen im Bereich Komponententechnologie und mehrschichtige Anwendungssysteme zu vertiefen.
Durch die enge Zusammenarbeit mit Samsung konnte außerdem eine reale
Anwendung unter ‚echten’ Bedingungen erstellt werden. Es handelte sich um
eine praxisnahe Projektarbeit, welche von der Ist/Soll Aufnahme, in diesem Fall den Besprechungen mit den Fachabteilungen, über die Modellierung des Systems, bis hin zur Implementierung reichte.
Für Samsung ergab sich mit dieser Diplomarbeit die Chance, einen Überblick über die verschiedenen Technologien zu erhalten. Weiterhin wurde die Arbeit mit einem einsetzbaren System abgeschlossen, welches von Samsung in einem produktiven Umfeld genutzt werden kann. Gerade im Großkundengeschäft sollte mit dem Serviceangebot des Kundeninformationssystems eine weitere Festigung der Marktposition erreicht werden. Wobei die durch das Web gebotenen Informationen auch für kleinere Kunden interessant sind, da gerade bei diesen eine endgültige Bestätigung ihrer Bestellungen ausbleibt. Mit Hilfe des erstellten Systems können beteiligte Kunden sich selbst ein Bild über den Status ihrer Geschäfte mit Samsung einholen. Dies bietet nicht nur einen Mehrwert für den Kunden, sondern reduziert auch für Samsung die Kosten des Kundenservices.
1.5 Bedeutung von Kundeninformationssystemen
E-Business ist in den letzten Jahren zu einem der Schlagwörter der Informatik geworden. Wenn auch e-Commerce - Internetshops - der bekannteste Vertreter der Sparte ist, sind reine Informationssysteme die via Internet verfügbar sind, nicht zu vergessen. Eines der bekanntesten Beispiele ist das Tracking-System von United Parcel Service.
Über solche Systeme werden dem Kunden Informationen aus dem System des Anbieters im Internet verfügbar gemacht. Das bedeutet, dass die Informationen
Einleitung
direkt, aktuell und zeitlich unabhängig verfügbar gemacht werden. Service- eines Kundeninformationssystem können kostengünstiger als
1.6 Kapitelübersicht
Kapitel 2 erläutert den Begriff Komponentenarchitektur, wobei das von Microsoft spezifizierte Component Object Model (COM) im Vordergrund steht. In dieses Modell soll ein technischer Einblick gegeben werden. Hierbei soll aufgezeigt werden, wo bestimmte Konzepte der COM-Architektur ihre Wurzeln haben. Weiterhin wird die Interoperabilität der COM-Programmierung in C++ und Visual Basic untersucht.
In Kapitel 3 werden Applikationsserver und deren Konzept beschrieben. Hier wird der Microsoft Transaction Server und der Gemstone/J Applikationsserver näher untersucht. Neben einer allgemeinen Vorstellung von Applikationsservern wird die Transaktionsunterstützung ausführlich untersucht. Abschließend wird erläutert, inwieweit die beiden Architekturen eine Persistenz-Unterstützung bieten.
Kapitel 4 befasst sich mit dem Thema Wrapping von Legacy-Systemen. Am Beispiel von SAP R/3 und SAPs Anwendungsprogrammierschnittstelle (Business Application Programming Interface, kurz BAPI) werden relevante Begriffe und deren Möglichkeiten erklärt. Am Ende des Kapitels soll Microsofts Universal Data Access (UDA) Architektur vorgestellt werden. Kapitel 5 stellt die von mir im Rahmen der Diplomarbeit erstellten Teile des Systems vor. Dies sind die Komponenten, welche die Anbindung an das R/3 System realisieren, sowie einen Teil der Login-Funktionalität und letztlich das Administrator-Frontend des Systems.
Kapitel 6 enthält eine abschließende Meinung und gibt einen weiteren Ausblick zu den behandelten Themen.
Im Anhang befindet sich das Quellenverzeichnis, ein Abkürzungsverzeichnis, sowie relevante Teile des Quellcodes.
Einleitung
Für das Verständnis der Arbeit setze ich vom Leser Grundlagen verteilter Anwendungen, sowie Middleware-Technologien voraus. Weiterhin ist ein Grundverständnis von objektorientierten Programmiersprachen notwendig.
2 Komponentenarchitekturen
Einleitend wird begründet, warum die Verwendung von Komponenten sinnvoll ist. Anschließend werden die Anforderungen der Komponentenarchitekturen COM und EJB gegenübergestellt. COM wird dann näher erläutert, wobei eine ausführliche Einführung in die technischen Grundlagen gegeben wird. Abschließend wird auf die Interoperabilität zwischen C++ und Visual Basic in der COM-Programmierung eingegangen.
2.1 Einführung
Das Prinzip Komponenten einzusetzen und somit eine Wiederverwendbarkeit und Reduzierung der Komplexität zu erreichen, ist in vielen Bereichen der Technik state of the art. So sind integrierte Schaltkreise (ICs) oder auch die komplette Zulieferung eines Motors in der Automobilindustrie typische Beispiele für eine Komponententechnik.
Das Prinzip der Komponententechnik besteht darin, komplexe Funktionalitäten in eine Black-Box - die Komponente - zu packen. Der Benutzer der Komponente ist nur über ihre Schnittstelle zur Außenwelt informiert. Wie die Komponente ihre Funktionalität umsetzt, ist unbedeutend. Dieses Prinzip ist unter dem Begriff „Informationhiding“ bekannt.
So bietet die Verwendung von Komponenten in der Informatik die Möglichkeit, die Komplexität einer großen monolithischen Applikation in kleinere überschaubare Komponenten zu zerteilen. Durch diesen Ansatz wird Wiederverwendbarkeit, Austauschbarkeit und eine bessere Modifizierbarkeit des gesamten Systems erreicht.
2.2 Einordnung
Komponentenarchitekturen im Rahmen der Softwareentwicklung können nicht lösgelöst betrachtet werden. Sie verwenden meist eine bewährte Middleware zur Kommunikation mit anderen Komponenten und ihren Clients. Diese Kommunikation kann auch über ein Netzwerk stattfinden. Auf den heutigen Komponentenmodellen setzen meist Applikationsserver auf, die eine Laufzeitumgebung und Dienstleistungen für diese bieten. Jedoch ist
Komponentenarchitekturen
dies kein Muss, das Komponentenmodell COM wurde für einen direkten Betrieb konzipiert und stellt eine Laufzeitumgebung im Betriebssystem zur Verfügung. Die nachfolgende Abbildung zeigt schematisch das Zusammenspiel der verschiedenen Elemente:
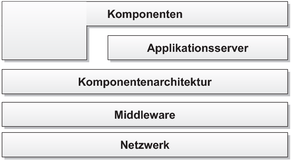
Abbildung 2.1 - Zusammenspiel zwischen Komponenten, Applikationsservern, Komponentenarchitekturen, Middleware und dem Netzwerk
2.3 Konzepte
Einleitend soll keine eigene Definition des Begriffs „Komponentenarchitektur“ gegeben werden. Vielmehr wird untersucht, wie Microsoft und Sun ihre Komponentenarchitekturen selbst definieren, wo Unterschiede zu sehen und wie diese zu bewerten sind.
Komponentenarchitekturen
Microsofts Component Object Model (COM)
Entnommen aus der COM-Spezifikation [Mic95, Kapitel 1 - Seite 3], sieht Microsoft folgende nachteilige Gründe an traditionellen Anwendungen, welche durch eine Komponentenarchitektur verbessert werden sollen: „I. Today’s applications are large and complex — they are time-consuming to develop, difficult and costly to maintain, and risky to extend with additional functionality.
II. Applications are monolithic — they come pre-packaged with a wide range of features but most features cannot be removed, upgraded independently, or replaced with alternatives.
III. Applications are not easily integrated — data and functionality of one application are not readily available to other applications, even if the
applications are written in the same programming language and running on the same machine.
IV. Programming models are inconsistent for no good reason. Even when applications have a facility for cooperating, their services are provided to other applications in a different fashion from the services provided by the operating system or the network. Moreover, programming models vary widely depending on whether the service is coming from a provider in the same address space as the client program (via dynamic linking), from a separate process on the same machine, from the operating system, or from a provider running on a separate machine (or set of cooperating machines) across the network.“ [Mic95 - Kapitel 1, Seite 3]
Microsofts Anforderungen
Welche Anforderungen an eine Komponentenarchitektur können hieraus abgeleitet werden?
Ist ein Anwendungssystem in einzelne, unabhängige Komponenten zerteilt, so sind Teile des Systems besser wiederverwendbar. Das gesamte System ist besser erweiterbar und die Implementierung einzelner Komponenten ist besser änderbar, wobei die Schnittstellen dieser Komponenten konstant bleiben müssen.
Komponentenarchitekturen
Eine Komponentenarchitektur muss daher Eigenschaften wie Wiederverwend- und Erweiterbarkeit unterstützen. Das Konzept der Architektur muss die
Implementierung von der Schnittstelle trennen. Abhängigkeiten zwischen diesen müssen strikt untersagt werden.
Weiterhin ist es wichtig, dass ein dynamisches Binden der Komponente an den Client möglich ist, denn nur so kann eine Komponente ersetzt oder geändert werden, ohne dass der Client neu erstellt werden muss. Auch muss der Programmierer der Komponenten diese ändern können, ohne dass die Neukompilierung aller Clients erforderlich ist. Diese Änderung darf nur die Art und Weise der Implementierung betreffen. Die Schnittstelle der
Komponenten muss konstant bleiben. Nach [Mic95, Kapitel 2 - Seite 3ff] kann die Schnittstelle einer COM-Komponente durchaus erweitert werden. Dabei
wird jedoch aus der Sicht eines alten Clients die Konstanz der Schnittstelle gewahrt. Dazu ausführlich mehr im folgenden Kapitel. Als Microsoft COM definierte, war Hauptspeicher noch eine sehr knappe Ressource. So sollte es möglich sein, eine Komponente nur einmal in den Hauptspeicher laden zu müssen, diese aber von mehreren Clients verwendet werden kann.
Außerdem muss es für den Client transparent sein, wie und wo die Komponente physikalisch abgelegt ist. Es ist unerheblich, ob sie lokal vorliegt oder über ein Netzwerk darauf zugegriffen wird. Weiterhin darf es für den Client keinen Unterschied machen, ob sie im gleichen oder in einem separaten Prozessadressraum ausgeführt wird.
Microsoft definiert mit dem Component Object Model die Grundlage einer Komponententechnologie für alle Bereiche der Windows Plattform. So ist COM nicht nur für Komponenten geeignet die Geschäftslogik implementieren, vielmehr dient COM beispielsweise auch als Grundlage der hoch performanten Grafikbibliothek DirectX. COM ist aber auch die Basis für die ActiveX Steuerelemente.
Sun Microsystems Enterprise JavaBeans (EJB)
Mit der Java 2 Plattform - Enterprise Edition - welche den Enterprise JavaBeans
Standard einschließt, fokussiert Sun die Anwendungsdomäne der serverbasierten Komponenten die Business-Logik implementieren.10
Komponentenarchitekturen
Suns Anforderungen
Nun sollen die Ziele des Designs der Enterprise JavaBeans Architektur gezeigt werden.
Nach der EJB-Spezifikation [Sun99, Seite 19] ist die EJB-Architektur eine Standardkomponentenarchitektur für das Erstellen von verteilten objektorientierten Geschäftsanwendungen mit der Sprache Java. Die EJB Architektur reduziert die Komplexität solcher Anwendungen und macht das Programmieren derselben einfacher. Ein Programmierer benötigt keine Kenntnisse von komplizierten low-level APIs. Das bedeutet, Details wie Multi-Treading, Connection-Pooling oder Skalierbarkeitsmechanismen werden vom Applikationsserver des EJB übernommen.
Die Java-Philosophie „write once, run anywhere“ gilt auch für EJB. Ein Enterprise Java Bean kann - zumindest theoretisch - ohne Neukompilierung
oder Quellcodeveränderung auf beliebigen Plattformen eingesetzt werden.
Ebenfalls wird festgelegt, dass das Entwickeln einer EJB-Anwendung mit Werkzeugen verschiedener Hersteller möglich sein soll.
Der EJB-Standard definiert, wie die Entwicklung, das Roll-out und der Einsatz der EJB-Architektur auszusehen hat. Sun spezifiziert weiterhin, dass die EJB-Architektur eine Interoperabilität zwischen EJB und Programmiersprachen neben Java unterstützt. Dies ist besonders für die Integration von Legacy Systemen wichtig. Ebenfalls ist der EJB-Standard mit CORBA kompatibel, so dass alle CORBA-kompatiblen Clients einen Zugriff auf den EJB-Applikationsserver durchführen können.
Charakterisiert man die Eigenschaften des Standards, kann man zusammenfassend sagen, dass Enterprise JavaBeans flexibel, wiederverwendbar, portabel, schnell entwickelbar und herstellerübergreifend sind.
Zusammenfassung
Vergleicht man die Anforderungen von COM und EJB wird deutlich, dass es sich zwar in beiden Fällen um Komponentenarchitekturen handelt, jedoch verschiedene Zielsetzungen zugrunde liegen.
Obwohl beide Technologien als „Komponentenarchitektur“ bezeichnet werden, sind folgende Unterschiede definiert:
Komponentenarchitekturen
Nach [Mic95, Kapitel 1 - Seite 6] definiert sich COM wie folgt: „The Component Object Model is an object-based programming model designed to promote software interoperability; that is, to allow two or more applications or “components” to easily cooperate with one another, even if they were written by different vendors at different times, in different programming languages, or if they are running on different machines running different operating systems.”. Aufgrund dieser Definition und der Tatsache, dass COM als Basis für beliebige Subsysteme von Windows konzipiert wurde, sind die Eigenschaften
Sprachunabhängigkeit, dynamische Bindung an eine Clientanwendung und
Transparenz der Implementierung primäre Themen in COM. Obwohl COM nicht ausschließlich zur Erstellung von Komponenten in einem N-Tier Umfeld für die Implementierung von Geschäftslogik entwickelt wurde, kann es ebenfalls hierfür eingesetzt werden. Auf diesen Teil von COM soll im Kapitel 3 dieser Arbeit eingegangen werden.
Nach [Sun99, Seite 19] ist die EJB-Architektur eine Standard-Komponentenarchitektur für verteilte, objektorientierte Geschäftsanwendungen. Somit ist der Anwendungsbereich spezifischer definiert. Hieraus ergibt sich, dass Anforderungen wie die Unterstützung von Diensten - Transaktionsunterstützung, Persistenz, Skalierbarkeit oder Objekt-Pooling - in die Spezifikation aufgenommen wurden.
2.4 COM / DCOM
Beginnend soll ein allgemeiner Überblick zu COM gegeben werden. Anschließend wird auf die technische Seite und deren Gegebenheiten eingegangen. Hierbei soll im Vordergrund stehen, warum bestimmte Konzepte, wie beispielsweise die Standardschnittstelle IUnknown, von COM überhaupt notwendig sind.
Allgemeine Konzepte
Um den jeweiligen Anforderungen gerecht zu werden, können COM-Komponenten in 3 verschiedenen physikalischen Modellen erstellt werden: Prozessinterner Server (Inproc Server)
Prozessexterner, lokaler Server (Local Server oder Outproc Server) Entfernter Server (Remote Server)
Komponentenarchitekturen
Abbildung 2.2 zeigt die 3 Modelle in ihren unterschiedlichen Formen:
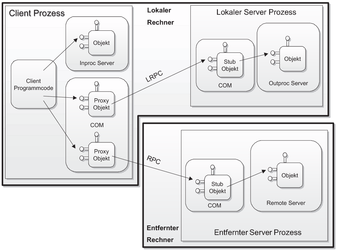
Abbildung 2.2 - Überblick der COM-Modelle Prozessinterne Server stellen den performantesten Zugriff auf eine COM-Komponente dar. Die Komponente wird im gleichen Prozessadressraum wie der Client erstellt. Daher der von Microsoft gebrauchte Name „Inproc“. Dies ist eine Abkürzung für in-process. Das bedeutet, die Komponente muss als dynamische Laufzeitbibliothek (engl. dynamic link library, kurz DLL) implementiert werden, wobei diese zur Laufzeit dynamisch in den Client eingebunden wird. Dieser Vorgang wird von der COM-Laufzeitbibliothek für den Client transparent durchgeführt. Der Vorteil hierbei ist, dass die Kommunikation zwischen Client und Komponente sehr schnell ist, da sie nicht über Prozessgrenzen hinweg gehen muss und weiterhin kein Kontextwechsel notwendig ist. Ein Absturz der Komponente bedeutet aber auch einen Absturz des Clients und umgekehrt. Wie die obige Grafik illustriert, gehen Aufrufe des Clients direkt an den prozessinternen Server. Dies ist möglich, da der Client auf den Speicherbereich des Servers zugreifen kann.
Prozessexterne lokale Server sind eine weitere Möglichkeit, wie eine COM-Komponente realisiert werden kann. Sie werden auch Outproc-Server genannt, wobei Outproc für out-of-process steht, das bedeutet, dass der Server in einem separaten Prozessadressraum ausgeführt wird. Da Client und Server sich nicht einen Prozessadressraum teilen müssen, führt ein Absturz des einen nicht zwangsläufig zum Absturz des anderen. Die Kommunikationsgeschwindigkeit
Komponentenarchitekturen
ist jedoch wesentlich langsamer als bei prozessinternen Servern, da Methoden- über Prozessgrenzen hinweg gehen.
Für die Kommunikation über Prozessgrenzen hinweg werden Proxy- bzw. Stub-Objekte benötigt. Das Proxy-Objekt repräsentiert das Server-Objekt für den Client. Das bedeutet, alle Aufrufe des Client gehen nicht an das eigentliche Server-Objekt, sondern an das Proxy-Objekt im Prozessadressraum des Clients. Dieser nimmt eingehende Aufrufe entgegen, verpackt (marshalling) die Parameter und sendet sie über einen Mechanismus ähnlich den Remote Procedure Calls (RPC) an den Server-Prozess.
Dort werden die Aufrufe vom Stub-Objekt entgegengenommen, die Parameter werden entpackt (unmarshalling) und an das eigentliche Serverobjekt weitergeleitet. Der Client wird also für das Server-Objekt durch das Stub-Objekt repräsentiert. Sendet der Server Daten an den Client zurück oder ruft der Server eine Callback-Routine auf, so wendet sich der Server an das Stub-Objekt. Dieses Objekt übernimmt die eigentliche Kommunikation mit dem Proxy-Objekt, welches den Aufruf an den Client weitergibt. Entfernt ausgeführte Komponenten, sogenannte Remote-Server, sind weitestgehend den prozessexternen COM-Servern ähnlich. So gibt es ebenfalls Proxy- und Stub-Objekte, welche die Aufrufe weiterleiten und die Parameter verpacken (marshalling). Der Unterschied besteht darin, dass die Komponente auf einem anderen Rechner ausgeführt wird, was jedoch von der COM-Laufzeitumgebung für den Client transparent gemacht wird. Der Client kann so die gleichen API-Aufrufe verwenden wie für den lokalen Fall. Für den Client ist die Art, wie und wo die Komponente ausgeführt wird, somit transparent. Microsoft bezeichnet dies als „Location Transparancy“ [Mic95, Kapitel 3 - Seite 6]. Hiermit ist der IV. Punkt der Microsoft Anforderung erfüllt. Mit der Einführung eines verteilten Komponentenmodells, namentlich „Distributed Component Object Model“ (DCOM), erweiterte Microsoft die COM-API. Es existieren zusätzliche Funktionen, die für entfernte Aufrufe besonders geeignet sind. Diese Funktionen können auch für den prozessexternen, lokalen oder prozessinternen Einsatz gebraucht werden. Sie bieten jedoch zusätzliche Funktionalität, wie explizite Angabe des entfernten Rechnernamens oder Sicherheitsfunktionalität. Grundsätzlich müssen entfernte Komponenten als EXE-Datei erstellt werden. Möchte man jedoch auch eine entfernte Komponente als DLL erstellen, so wird ein zusätzlicher Ausführungsprozess -
Komponentenarchitekturen
„surrogateprocess“ genannt - benötigt, in dessen Kontext die DLL ausgeführt wird. Der Microsoft Transaction Server stellt einen solchen Surrogateprocess für DLLs zur Verfügung.
Sprachunabhängigkeit
Für die Windows-Umgebung stellt Microsoft eine Vielzahl von Programmiersystemen zur Verfügung. Aufgrund dieses heterogenen Sprach- und Entwicklungsumgebungsumfeldes, war eine Sprachunabhängigkeit der Komponentenarchitektur für Windows ein vordergründiges Ziel. Will man eine von der Programmiersprache unabhängige Wiederverwendbarkeit, darf die Klasse nicht als programmiersprachenabhängiger Quellcode vorliegen.
COM-Komponenten werden deshalb als bereits kompilierte ausführbare Datei wiederverwendet. Für eine Beschreibung der Schnittstellen definierte Microsoft einen Binärstandard, so dass eine Wiederverwendbarkeit auch zwischen verschiedenen Programmiersprachen möglich wird. Eine COM-Komponente kann von verschiedenen Programmiersprachen benutzt und erstellt werden und ist somit sprachunabhängig.
Technische Realisierung
Im Folgenden soll eine Einführung der COM Technologie gegeben werden. Die COM-Architektur beinhaltet folgende Konzepte: Schnittstellen, Implementierung und Apartments. Im Weiteren folgt eine Beschreibung der einzelnen Begriffe.
Schnittstellen
Client und Komponente kommunizieren über die Schnittstelle der Komponente miteinander. Schnittstellen definieren die Methoden mit den Ein- und Ausgabeparametern. So besitzt der Client keine Kenntnisse über die Implementierung der Komponente. Die Schnittstellen stellen den „Vertrag“ zwischen Komponente und Client dar.
Komponentenarchitekturen
Die Frage, warum eine Schnittstelle aus technischer Sicht benötigt wird, kann am besten an einem Beispiel geklärt werden.
Eine Verschlüsselungsklasse in C++ geschrieben könnte wie folgt aussehen:
class CKrypto { private: BSTR 1 m_buffer; CKey m_Key; public: CKrypto () {};
CKrypto (LPCSTR Text,CKey Key) : m_buffer(Text),m_Key(Key) {}; void Encrypt_TripleDES() { // Hier wird der Text verschlüsselt }; void Decrypt_ TripleDES() { // Hier wird der Text entschlüsselt };
void GetText(BSTR * Result) { // m_Buffer in Result zurückgeben }; };
Diese soll nun vertrieben werden. Welche Möglichkeiten gibt es?
Statische Bindung
Die traditionelle Lösung ist ein Vertrieb der Klasse als Bibliotheksdatei 2 , hier wird die Klasse - für den Benutzer nun als Komponente bezeichnet - statisch an den Client gebunden. Zu der Bibliotheksdatei würde er die dazugehörenden Header-Dateien ausliefern.
Nachteilig hierbei ist, dass jeder Nutzer auf C++ beschränkt bleibt. Wird weiterhin seine Komponente mehr als einmal auf einem Rechner benutzt, so entsteht eine Redundanz dadurch, dass jedes Programm den Code der Komponente einschließt. Dies kann bei sehr häufig verwendeten Komponenten, wie der Dialog „Datei Öffnen“, einen großen Bedarf an Speicherkapazität einnehmen. Ein weiterer negativer Punkt ist, falls die Komponente geändert werden muss, sei es weil ein Fehler gefunden wurde oder die Funktionalität optimiert wurde, alle Clients neu zu kompilieren sind. Dieses bedeutet in der
Komponentenarchitekturen
Praxis, dass die kompletten Clientanwendungen ausgetauscht werden müssen, worauf auch [SK99, Seite 10f] hinweist.
Dynamische Bindung
Der nächste Schritt ist eine dynamische Bindung der Komponente zur Laufzeit an den Client. Dies ist eine der Anforderungen von Microsoft an eine Komponentenarchitektur. Nun kann eine Komponente ausgetauscht werden, ohne dass ein Client neu kompiliert werden muss. Hierzu wird die Komponente nicht mehr in einer LIB-Datei ausgeliefert, sondern in eine dynamische Laufzeitbibliothek 1 kompiliert.
Um eine Klasse aus einer DLL-Datei zu exportieren, steht in Microsoft Visual C++ das Schlüsselwort __declspec(dllexport) zur Verfügung. Für das oben beschriebene Beispiel sähe das wie folgt aus:
class __declspec(dllexport) CKrypto {…};
Hier wird die Klasse aus einer DLL exportiert. Dabei ergeben sich folgende gravierende Probleme.
Das erste Problem ist unter dem Namen „name mangling“ [SK99, Seite 12] oder „name decoration scheme“ [Gri97, Seite 52ff] bekannt. Bei der Erstellung der DLL vergibt der Compiler für jede Funktion einen eindeutigen Namen. Dieser formiert sich aus dem Klassennamen, dem Methodennamen und den Parametern. Hier ein Beispiel für eine Benennung:
void CKrypto::Encrypt_TripleDES()
dieser Funktion gibt der Compiler den folgenden symbolischen Namen:
?Encrypt_TripleDES@CKrypto@@QAEXXZ
Soll die DLL in einem Client verwendet werden, so sucht der Compiler(Linker) zur Übersetzungszeit des Clients den vergebenen Namen in der DLL. Wurde nun die DLL mit einem anderen Compiler erstellt, welcher ein anderes Schema zur Erzeugung der Namen verwendet hat, so kann der Compiler(Linker) des
Komponentenarchitekturen
Clients die Namen nicht finden und meldet ein unaufgelöstetes Symbol beim Binden des Clients.
Compiler verwenden verschiedene Schemata zur typsicheren Bindung, um Funktionen und Methoden eindeutig zu kennzeichnen. Dieses Schema variiert in unterschiedlichen Compilern und deren Versionen. Das bedeutet weiterhin, dass man für jede Entwicklungsumgebung eine eigene DLL ausliefern muss.
[SK99, Seite 12f] gibt folgende mögliche Umbenennungen von verschiedenen Herstellern an: Symantecs Umbennenungsschema
??0CKrypto@@QAEX@Z ??1CKrypto@@QAEX@Z ?Encrypt_TripleDES@CKryptoQAEXXZ Microsofts Umbennenungsschema
??0CKrypto@@QAE@ABV0@@Z ??1CKrypto@@QAE@Z ?Encrypt_TripleDES@CKrypto@@QAEXXZ Inprise Umbennenungsschema
@CKrypto@$bctr$pqv @CKrypto@$bctr$pv @CKrypto@Encrypt_TripleDES$qv
[Gri97, Seite 55] empfiehlt daher, keine Klassen aus DLLs zu exportieren und alle exportierten Funktionen mit extern "C" zu kennzeichnen. Jedoch ist die Einschränkung keine Klassen zu verwenden, nicht akzeptabel, beziehungsweise es ist ebenso unakzeptabel, dass nur eine Entwicklungsumgebung verwendet werden kann. Diese Möglichkeit scheidet dadurch für eine Komponentenarchitektur aus.
[SK99, Seite 13 f.] sieht jedoch noch weitreichendere Probleme. Selbst wenn man sich auf eine Entwicklungsumgebung einigen würde, bzw. ein standardisiertes Name-Mangling Schema verwenden würde, existierte ein weiteres Problem.
Wenn man eine Klasse aus einer DLL exportiert, wird das gesamte Klassenlayout exportiert. Das bedeutet alle Methoden, auch private, geschützte und statische Variable sind dem Client bekannt. Hiermit wäre das Black-Box Prinzip - der Client kennt nur die öffentliche Schnittstelle - gebrochen. Soll nun
Komponentenarchitekturen
die DLL nachträglich geändert bzw. erweitert werden, müsste der Client wiederum neu kompiliert werden und genau das galt es zu verhindern. Deshalb muss man den nächsten Schritt von der „Klassenbasierten Programmierung“ hin zur „Schnittstellenbasierten Programmierung“ durchführen.
Schnittstellenbasierte Programmierung
Zwar enthält C++ die syntaktischen Mechanismen der Schnittstellenkapselung (private, protected und public), jedoch verhindern diese nicht, dass dem Client nicht schnittstellenbezogene Informationen geliefert werden, sobald man die Klasse aus einer DLL exportiert.
Damit dem Client ausschließlich Informationen über die Schnittstelle bekannt sind, benutzt COM abstrakte Basisklassen. Die abstrakte Basisklasse besteht aus einer beliebigen Anzahl von Funktionszeigern. Die Tabelle von Funktionszeigern wird auch als „virtual Table“ (vTable) bezeichnet. Die Funktionszeiger verweisen auf die Implementierung in einer Subklasse, wie es Abbildung 2.3 darstellt.
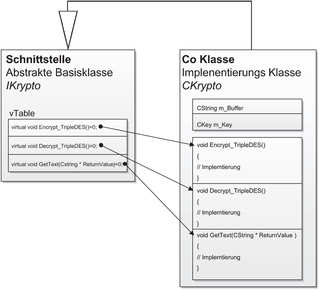
Abbildung 2.3 - Beziehung zwischen Schnittstelle und ihrer Implementierung
Komponentenarchitekturen
In Anlehnung an das obige Beispiel würde eine abstrakte Basisklasse folgendermaßen aussehen:
class IKrypto { public: virtual void Encrypt_TripleDES ()=0; virtual void Decrypt_TripleDES ()=0; virtual void GetText (BSTR * ReturnValue)=0; };
Die Klasse, welche die Implementierung enthält, erbt nun von der Schnittstelle: class CKrypto : public IKrypto { // Implementierung wie oben };
Dem Client wird ausschließlich die abstrakte Basisklasse zur Verfügung gestellt. Programmiert man einen COM-Server in der Sprache C, so verwendet man anstatt der abstrakten Basisklasse eine Variable, die ein Array von Funktionszeigern enthält. Visual Basic, Delphi und alle weiteren Sprachen, die eine COM-Unterstützung bieten, richten sich nach den durch C/C++ definierten Arrays von Funktionszeigern und bieten eine transparente Unterstützung dieser.
Unveränderlichkeit von Schnittstellen
Zusammenfassend kann man sagen, dass das Konzept der Schnittstellen in C++ über abstrakte Basisklassen realisiert wird. Über diese Schnittstellen wird der Client von der Implementierung und deren Details getrennt. Die Schnittstelle stellt so den unveränderlichen Vertrag zwischen Server und Client dar. Dies ist das fundamentale Prinzip der schnittstellenbasierten Programmierung. Will man der Komponente neue Methoden und Funktionalitäten hinzufügen, so
muss man eine neue Schnittstelle erstellen und diese der Komponente hinzufügen.
Komponentenarchitekturen
Die Standardschnittstelle IUnknown
Wie kann ein Client die erweiterten Schnittstellen einer Komponente erreichen? Jede COM-Komponente muss die Schnittstelle IUnknown unterstützen. Diese bietet zwei Funktionen: Abfragen von weiteren Schnittstellen Referenzzählung IUnknown enthält 3 Methoden, 2 für die Referenzzählung und eine weitere für das Anfordern von weiteren Schnittstellenzeigern.
class IUnknown { public: virtual HRESULT QueryInterface( REFIID riid, void ** ppvObject) = 0; virtual ULONG AddRef(void) = 0; virtual ULONG Release(void) = 0; };
Auf die Referenzzählung wird weiter unten eingegangen. Ein Client kann über die Methode QueryInterface(REFIID idd, void** ppvObject) der Schnittstelle IUnknown einen Server abfragen, ob er eine Schnittstelle mit der ID iid unterstützt. Ist dies der Fall, wird ein Zeiger auf diese Schnittstelle in ppvObject zurückgegeben. Durch dieses Prinzip kann die Funktionalität einer Komponente erweitert werden, so dass jedoch auch Clients, die nur einzelne Schnittstellen kennen, weiter mit der neueren, komplexeren Komponente arbeiten können. Hierzu ein Beispiel. Die obige Kryptographiekomponente soll um den IDEA-Algorithmus erweitert werden.
class IKrypto2 : public IUnknown { public: virtual void Encrypt_IDEA()=0; virtual void Decrypt_IDEA()=0; };
Auch die Schnittstelle IKrypto muss von der Klasse IUnknown erben.
class IKrypto : public IUnknown { … }; Die Klasse CKrypto muss nun von beiden Schnittstellen erben:
Komponentenarchitekturen
class CKrypto : public IKrypto, public IKrypto2 { // I.) Implementierung von IKrypto, wie oben // II.) Zusätzlich Implementierung von IKrypto2
// III.) Implementierung der Methoden von IUnknown };
Abfragen von Schnittstellen
Ein Client kann so eine Komponente abfragen, ob sie weitere Schnittstellen unterstützt. Wird dies unterstützt, kann ein Client die erweiterte Funktionalität nutzen. Andernfalls kann der Client auch nur über ihre ursprüngliche Schnittstelle kommunizieren.
Ein alter Client kann so auch mit neuen Komponenten zusammenarbeiten. Umgekehrt ebenso.
Im Beispiel oben könnte ein Client wie folgt die Komponente Krypto über ihre Schnittstellen abfragen und die neuste Schnittstelle verwenden:
IKrypto * pKrypto;
// Hier wird die Komponente erstellt und pKrypto enthält einen Zeiger auf sie IKrypto2 * pKryptoEx=NULL;
pKrypto->QueryInterface( IID_IKrypto2 , (void**)& pKryptoEx ); if ( pKryptoEx != NULL ) pKryptoEx->Encrypt_IDEA(); // Neue Funktion nutzen else pKrypto->Encrypt_TripleDES(); // Alte Funktion nutzen Microsoft spezifiziert nach [Mic95, Kapitel 3 - Seite 9] folgende Anforderungen für die Implementierung der Methode QueryInterface() in einem COM-Server: QueryInterface() muss symmetrisch sein. Besitzt ein Client einen Zeiger auf eine Schnittstelle und fordert er das Gleiche nochmals an, so muss dieser Aufruf erfolgreich sein.
pKrypto ->QueryInterface(IID_IKrypto,(void**)& pKrypto) => muss erfolgreich sein
Abbildung 2.4 - QueryInterface() muss symmetrisch sein
Komponentenarchitekturen
QueryInterface() muss reflexiv sein. Besitzt ein Client einen Zeiger auf eine Schnittstelle und fordert er erfolgreich eine zweite Schnittstelle an, so muss das Anfordern der ersten Schnittstelle auf die zweite Schnittstelle ebenfalls möglich sein.
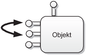
Abbildung 2.5 - QueryInterface() muss reflexsiv sein QueryInterface() muss transitiv sein. Besitzt ein Client einen Zeiger auf eine Schnittstelle und fordert er erfolgreich eine zweite Schnittstelle an und ist es weiterhin möglich über diese zweite Schnittstelle eine dritte Schnittstelle anzufordern, so muss es auch möglich sein, direkt über die erste Schnittstelle die dritte Schnittstelle zu erreichen.
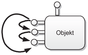
Abbildung 2.6 - QueryInterface() muss transitiv sein
Objekterstellung und Destruktion
Ein weiteres Problem stellt das Erstellen und Löschen der COM-Komponenten dar. Der Client hat keine Information über die implementierende Klasse, daher kann dieser die Komponente auch nicht erstellen oder löschen. Beispielswiese
Komponentenarchitekturen
fehlem dem Client Informationen über die Größe des anzulegenden Speichers. Die Instanziierung muss in Eigenverantwortung der COM-Komponente geschehen.
Nun soll die Frage nach der Objektdestruktion geklärt werden. COM definiert, dass jede Komponente einen eigenen Referenzzählmechanismus implementiert. Das bedeutet, jedes Objekt zählt selbst, wie oft es angefordert und wieder freigegeben wurde. Läuft dieser Referenzzähler auf null, deallokiert sich das Objekt selbst. Zu diesem Zweck sind die beiden Methoden
void AddRef(); void Release();
der IUnknown Schnittstelle definiert. AddRef() erhöht den internen Zähler um eins. Release() dekrementiert den Referenzzähler um eins. Weiterhin prüft Release(), ob der Referenzzäher gleich null ist. Wenn dies der Fall ist, so deallokiert Release das eigene Objekt. Hier eine beispielhafte Realisierung der beiden Methoden:
void AddRef() { m_RefZaehler++; } void Release() { m_RefZaehler--; if ( m_RefZaehler == 0 ) delete this; }
Nun zur Objekterstellung. Der C++ Konstruktormechanismus kann nicht verwendet werden, wie das folgende Beispiel zeigt:
Ein Client, der einen leeren Schnittstellenzeiger auf IKrypto besitzt und nun eine Instanz anfordern möchte, kann nicht
IKrypto * myKrypto = new CKrypto();
aufrufen, da die Klasse CKrypto außerhalb der DLL nicht bekannt ist. Um die Eigenverantwortlichkeit zu realisieren, spezifiziert COM, dass jede COM-Klasse auch für die eigene Instanziierung zuständig ist, das heißt für jede Komponente muss eine Klassenfabrik existieren.
Diese Klassenfabrik wird wiederum als COM-Komponente realisiert und muss die Schnittstelle IClassFactory implementieren. Auch diese erbt wiederum von
Komponentenarchitekturen
IUnknown. Die Klassenfabrik ist zuständig für das Erstellen der COM-
Hier stellt sich die Frage, wie der Client eine Instanz der ClassFactory Komponente erhalten soll. Damit ein Client eine ClassFactory, also einen Schnittstellenzeiger darauf erhalten kann, wird eine Funktion namens DllGetClassObject() aus der DLL exportiert. Diese Funktion gibt einen Schnittstellenzeiger auf ein instanziiertes ClassFactory-Objekt zurückgibt. Die Funktion DllGetClassObject() wird mit extern "C" gekennzeichnet, so dass „name mangling“ Probleme vermieden werden. Abbildung 2.7 zeigt den Ablauf einer Objektinstanziierung:
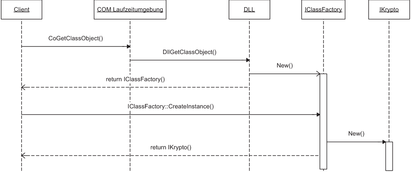
Abbildung 2.7 - Sequenzediagramm Instanziierung einer COM-Klasse Das Problem, wie ein Client eine Instanz einer COM-Klasse anlegen kann, wird in COM mehrstufig gelöst. Ein Client besitzt aber keine Informationen darüber, wie eine COM-Klasse konkret erstellt wird.
IDL - Interface Definition Language
Zu Anfang wurde die Sprachunabhängigkeit als eines der primären Ziele der COM-Architektur festgesetzt. Jedoch haben wir bis jetzt immer mit C bzw. C++ gearbeitet.
Wie können jedoch Sprachen wie Visual Basic oder Delphi COM-Komponenten einsetzen und erstellen? Grundlage jeder Interoperabilität zwischen
Komponentenarchitekturen
Programmiersprachen sind Typbibliotheken, welche aus einer IDL-Beschrei- erzeugt werden.
Bis hierher wurden die Schnittstellen in C++ Syntax erstellt und beschrieben. Notwendig ist aber eine sprachunabhängige Schnittstellenbeschreibungssprache, damit alle Programmierumgebungen ein COM-Objekt nutzen können. Die Object Management Group (OMG) hat die Interface Definition Language (IDL) als Schnittstellenbeschreibungssprache definiert. Sie dient dazu, die Schnittstellendefinitionen in einem einheitlichen Schema weiterzugeben, ohne sprachabhängige Standards, wie beispielsweise C Header-Dateien, für den Informationsaustausch notwendig zu machen. Microsoft hat die IDL um eigene Sprachbestandteile erweitert; diese Erweiterung heißt Microsoft Interface Definition Language - MIDL. Sie ist eine der beiden Grundlagen für Schnittstellenbeschreibungen in COM. Neben der MIDL hat Microsoft Typenbibliotheksdateien definiert, die Schnittstellen in einem weiteren sprachunabhängigen binären Format beschreiben. Der von Microsoft ausgelieferte MIDL-Compiler kompiliert aus einer MIDL-Datei folgende Dateien:
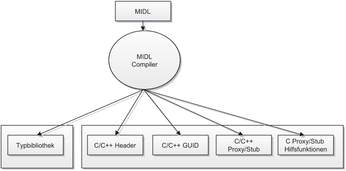
nur für C/C++ verwendbar Sprachunabhängig
ASCII Format binärer Standard
Abbildung 2.8- Dateigenerierung aus einer MIDL-Datei
Komponentenarchitekturen
C/C++ Header - Definitionen der Schnittstellenklassen bzw. Strukturen C/C++ UUID 1 Definitionen C/C++ Proxy/Stub Code Proxy/Stub Hilfsfunktionen in C
Typbibliothek
Aus der MIDL-Datei werden die Schnittstellenbeschreibungen für C/C++ erzeugt. Hierzu wird eine Header-Datei erzeugt. Weiterhin wird für eine
Verwendung in C/C++ eine Datei erzeugt, die alle durch die Komponente definierten GUIDs enthält.
Eine MIDL-Datei ist des Weiteren die Grundlage für Proxy/Stub-Dateien, die für einen prozessexternen bzw. verteilten Zugriff auf die Komponenten notwendig sind. Diese Dateien können auch selbst programmiert werden, was aber einen sehr aufwendigen und technisch komplizierten Vorgang darstellt. Das Erstellen des Proxy/Stub-Codes wird dem Programmierer vom MIDL-Compiler abgenommen.
Weiterhin werden aus einer MIDL-Datei die bereits angesprochenen Typbibliotheken erstellt. Sofern die MIDL-Datei eine solche spezifiziert hatte, erstellt der MIDL-Compiler eine sprachunabhängige binäre Schnittstellenbeschreibungsdatei. Nur mit Hilfe einer Typbibliothek ist es Sprachen wie Visual Basic, Delphi oder Microsoft Java möglich, eine COM-Komponente zu verwenden bzw. eine solche zu erstellen.
Die Schnittstellendefinition in MIDL für die Schnittstelle IKrypto sähe folgendermaßen aus:
Komponentenarchitekturen
[ uuid(A99E496B-35BF-4DC1-BA59-F7EBF9C37A1C), object ]
interface IKrypto : IUnknown { void Encrypt_TripleDES (); void Decrypt_TripleDES (); void GetText ([out] BSTR * ReturnValue); };
In den ersten vier Zeilen befindet sich eine Microsofterweiterung der IDL, hier wird die UUID der Schnittstelle spezifiziert. Das Schlüsselwort Object gibt an, dass es sich um eine COM-Schnittstelle handelt. Anschließend wird der Name der Schnittstelle definiert, gefolgt von der Schnittstelle, von dem sie erbt.
Alle COM-Schnittstellen müssen mindestens von IUnknown erben, um Mechanismen wie die Lebensdauer des Objektes und Schnittstellenabfrage zu unterstützen.
Damit der MIDL-Compiler auch die Typbibliothek erzeugen kann, benötigt die IDL-Datei noch einen „library“ Eintrag:
[ uuid(5E538679-3092-4489-AF69-EBC5BBAF15B9), helpstring("Krypto COM Server") ] library KryptoServer { [ uuid(1CB824C0-890A-4BE2-A33A-DFC52E2A805C), helpstring("Krypto Klasse") ] coclass Krypto { [default] interface IKrypto; interface IKrypto2; }; };
Hier werden für die Library eine UUID und ein Beschreibungstext vergeben. Der Eintrag „coclass“ definiert alle möglichen Schnittstellen für die Komponente. Auch diese coclass erhält eine UUID und eine Beschreibung. Mehr über IDL-Dateien, Typbibliotheken und „Interoperabilität von C++ und VB Komponenten“ im gleichnamigen Kapitel.
Komponentenarchitekturen
Implementierung
Nachdem die Schnittstellen einer Komponente definiert sind, folgt die Verknüpfung mit der Implementierung.
Wie bereits oben beschrieben, muss eine Klasse von der abstrakten Basisklasse, der Schnittstelle erben und die pur virtuell deklarierten Methoden implementieren.
COM unterscheidet zwei Typen von Klassen, die eine Schnittstelle implemetieren:
COM-Klassen
Sie stellen den Standardfall einer Implementierung dar. Synonym werden sie auch CoKlassen genannt. Durch sie werden die Schnittstellen implementiert. Die Klasse CKrypto ist eine solche COM-Klasse.
Klassenobjekte
Ein weiterer Typ sind Klassenobjekte. Dies sind Metaklassen zu den oben genannten COM-Klassen. So treten Klassenobjekte und COM-Klassen immer paarweise auf, dies ist ein Grundprinzip von COM [SK99, Seite 35]. Klassenobjekte dienen in erster Linie zwei Zwecken. Zum einen sind sie für die Instanziierung der mit ihnen gepaarten Klassen zuständig. Wie weiter oben bereits beschrieben, werden COM-Klassen durch eine Klassenfabrik erstellt. Diese Klassenfabrik - sie implementiert die Schnittstelle IClassFactory - ist ein Beispiel für ein Klassenobjekt.
Neben der Schnittstelle IClassFactory bietet COM eine weitere Standardschnittstelle für das Erstellen von COM-Klassen. Sie trägt den Namen IClassFactory2 und wird verwendet, wenn Lizenzberechtigungen eine Rolle spielen sollen.
Klassenobjekte werden von der COM-Laufzeitbibliothek statisch und global erstellt. So können sie statische, sowie gemeinsam genutzte Daten speichern. Die Lebensdauer eines Klassenobjektes beginnt mit dem der zugehörigen COM-Klasse, jedoch überlebt das Klassenobjekt die COM-Klasse und ist hierdurch ideal für das Speichern von statischen Variablen, beziehungsweise dem Implementieren von statischen Schnittstellen.
Komponentenarchitekturen
COM-Server
Der COM-Server ist der Lebensraum von COM-Klassen und deren Klassenobjekten.
Aus den drei Varianten - prozessinternen, prozessexternen und entfernten Komponenten - lassen sich zwei Modelle von COM-Servern ableiten. Für das prozessinterne Modell ist die Datei eine DLL. Für prozessexterne und entfernte Komponenten wird die Datei als EXE erstellt. Für einen Client ist es transparent, ob ein COM-Server als DLL oder EXE erstellt wurde. Der Programmierer des COM-Servers hingegen muss modellspezifische Unterschiede beachten. So unterscheidet sich die Programmierung eines DLL COM-Servers eklatant von der einer EXE. Wird der COM-Server als DLL erstellt, müssen mindestens zwei Funktionen exportiert werden.
int DllGetClassObject(REFCLSID rclsid, REFIID riid, LPVOID* ppv) int DllCanUnloadNow(void)
Die Erste ist die bereits oben beschriebene Funktion, mit der ein Client einen Zeiger auf ein ClassFactory Objekt erhalten kann. Die zweite Funktion prüft und liefert das Ergebnis an den Aufrufer, ob die DLL entladen werden kann. Da sich COM zentral auf die Registrierungsdatenbank von Windows stützt, muss eine COM-Komponente in ihr eingetragen werden. Hierzu sollte die Komponente die folgenden Funktionen aus der DLL exportieren, um eine Selbstregistrierung zur Verfügung zu stellen:
int DllRegisterServer(void) int DllUnregisterServer(void)
Sie werden von externen Programmen, wie dem MTS aufgerufen, um sich in der Registrierungsdatenbank einzutragen.
Wird der COM-Server als EXE-Datei erstellt, muss die void main() Funktion diese Registrierungsarbeiten durchführen können. Obwohl nicht in der COM Spezifikation enthalten, sollte ein prozessexterner COM-Server über $ <Dateiname> /RegServer
Komponentenarchitekturen
bzw. $ <Dateiname> /UnregServer
registriert bzw. gelöscht werden können, worauf auch [EE98, Seite 70] hinweist. Weiterhin muss ein EXE-Server seine COM-Klassen in der void main() Funktion bei der COM-Laufzeitumgebung mit dem API-Aufruf CoRegisterClassObject() anmelden, so dass die COM-Laufzeitumgebung über die aktuellen Einsprungpunkte der COM-Klassen informiert wird. Dies muss ein DLL-Server nicht, da sich Client und Server im gleichen Prozessadressraum befinden.
Apartments / Threading in COM
Microsoft definierte den COM-Standard mit Windows 3.1, das aus 16 Bit Code bestand. Damals unterstützte Windows noch kein Multi-Threading, wie [EE98, Seite 131] bemerkt. Jedoch musste auch damals schon ein Server mehrere gleichzeitige Verbindungen von Clients verarbeiten können [Gri97]. Diese Synchronisation wurde über die Windows-Nachrichtenwarteschleife erledigt. Als Multi-Threading in Windows Einzug hielt, musste auch COM auf Multi-Threading-Betrieb umgestellt werden. Damit aber auch vorher entwickelte COM-Komponenten weiterhin verwendbar blieben, musste ein Konzept erstellt werden, das eine Rückwärtskompatibilität sicherstellt. Nach [EE98, Seite 131] sollten alte, nicht thread-sichere Komponenten, nahtlos mit den neuen multithreaded Komponenten zusammenarbeiten können. Um diese Abwärtskompatibilität zu gewährleisten, wurde das Konzept der Apartments eingeführt. Wobei zu betonen gilt, dass es sich bei Apartments nur um eine konzeptionelle Entität handelt.
So wurde definiert, dass ein Thread immer in einem Apartment ausgeführt wird. Windows NT4 und Windows 9x unterscheidet zwei Typen von Apartments: single-threaded und multi-threaded Apartments.
Apartment-Threading
Ein single-threaded Apartment (STA) enthält immer nur einen Thread. Verwenden mehrere Threads die Komponente gleichzeitig, so synchronisiert die COM-Laufzeitumgebung die Aufrufe über eine Windows Nachrichten-
Komponentenarchitekturen
warteschlange, so dass ein thread-sicheres Verhalten sichergestellt wird. Der Programmierer muss keine Synchronisationsmechanismen selbst erstellen.
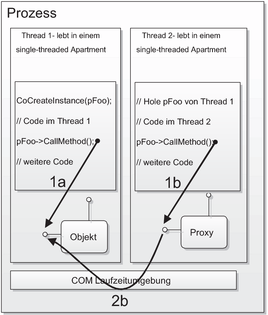
Abbildung 2.9 - Single-threaded Apartments Beide Threads ‚leben’ in verschiedenen Apartments. Nur der Thread, der das COM-Objekt erzeugt hat, kann direkt darauf zugreifen. Alle anderen Threads verwenden ein Proxy-Objekt für den Zugriff, wobei die COM-Laufzeitumgebung die Aufrufe serialisiert, um ein thread-sicheres Verhalten zu gewährleisten.
Komponentenarchitekturen
Free-Threading
Ein multi-threaded Apartment (MTA) kann einen oder mehrere Threads enthalten. Die COM-Laufzeitumgebung führt keine Synchronisationen der Threads durch. Der Programmierer muss die Thread-Sicherheit seiner Komponente sicherstellen. Da eingehende Aufrufe parallel bearbeitet werden können, stellt dieser Apartmenttyp die höchste Performance zur Verfügung und sollte für Komponenten verwendet werden, die Hintergrunddienste verrichten.
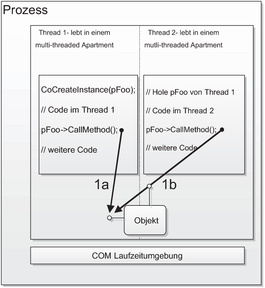
Abbildung 2.10 - Multi-threaded Apartments Alle Threads leben im gleichen Apartment. Verschiedene Threads können direkt und parallel auf das gleiche COM-Objekt zugreifen. Synchronisationsmechanismen müssen durch den Programmierer erstellt werden.
Threading in C++ und Visual Basic
C++ unterstützt alle genannten Threading-Modelle. Hierbei ist es dem Programmierer überlassen, ob er sich für das effizientere und - aufgrund der Synchronisationsprobleme - aufwendigere Free-Threading-Modell entscheidet oder ob er das leichter umzusetzende Apartment-Threading-Modell vorzieht.
Komponentenarchitekturen
Visual Basic hingegen unterstützt ausschließlich das Apartment-Threading- da Visual Basic generell keine multi-threaded Anwendungen erstellen kann. So ist es nicht möglich, einen zweiten Thread aus einer VB Anwendung zu starten.
Nachteilig wird diese Einschränkung erst, wenn Visual Basic und C++ Clients und COM-Komponenten zusammenarbeiten sollen. So verliert man die Vorteile, die eine multi-threaded Komponente mitbrachte, wenn sie in Zusammenarbeit mit einem apartment-threaded Client kommt. Die COM-Laufzeitbibliothek stellt in einem solchen Fall die korrekte Zusammenarbeit sicher, jedoch mit der Einschränkung, dass die Vorteile des multi-threaded COM-Objektes verloren gehen.
Neutrale Apartments
COM+ definiert einen weiteren Apartment Typ: Neutrale Apartments (NA). Ein neutrales Apartment besitzt keinen eigenen Thread, vielmehr kann jeder Thread in einem neutralen Apartment ausgeführt werden. Das hat den Vorteil, dass ein Aufruf in ein neutrales Apartment keinen Thread-Wechsel zur Folge hat.
In single-threaded Apartments wurde die Synchronisation über Nachrichtenwarteschleifen realisiert. In einem multi-threaded Apartment steht eine Synchronisation nicht automatisch zur Verfügung. In einem neutralen Apartment hingegen kann der Synchronisationsmechanismus mittels des COM+ Explorers, einem Administrator-Frontend, zur Laufzeit ausgewählt werden. Microsoft benennt dies „Attribut-basiertes Programmieren“, das bedeutet, ein Programmierer setzt nur Attribute für seine Komponente. Diese bestimmen das Verhalten. Eine Synchronisation wird also von der COM-Laufzeitumgebung zur Verfügung gestellt, sie muss aber nicht genutzt werden.
COM und die Windows-Registrierungsdatenbank
Zur Identifizierung der Elemente von COM werden universelle und eindeutige Schlüssel (engl. universally unique identifier, kurz UUID) verwendet, welche synonym auch Globally Unique Identifier (GUID) genannt werden. Dies sind 128-Bit lange Integerzahlen. Benötigt man für eine eigene Komponente eine UUID, so kann diese über ein von Microsoft bereitgestelltes Werkzeug generiert
Komponentenarchitekturen
werden. Durch einen speziellen Algorithmus wird die Eindeutigkeit einer UUID garantiert.
COM speichert und bezieht alle Informationen über Komponenten, Server, Typbibliotheken und Schnittstellen aus der Windows-Registrierungsdatenbank. Hier werden für COM-Komponenten Informationen über ihre Klassen-UUIDs, Schnittstellen-UUIDs und Typbibliotheks-UUIDs abgelegt. Im Falle eines DLL-Servers ist neben diesen UUIDs, auch das von der Komponente verwendete Threading-Modell, in der Registrierungsdatenbank abgespeichert. Hier ist auch gespeichert, um welches Modell es sich handelt: prozessintern, prozessextern oder entfernt. Ein weiterer Eintrag speichert den Namen der Datei, welche die COM-Komponente enthält und wo diese Datei auf der Festplatte zu finden ist.
Hier ein Auszug aus der Windows-Registrierungsdatenbank:
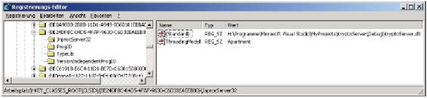
Abbildung 2.11 - Ausschnitt aus der Windows-Registrierungsdatenbank Unter dem Knotenpunkt der UUID der COM-Klasse, befinden sich die Einträge für den InprocServer32, die ProgID, die Typbibliothek und eine versionsunabhängige ProgID.
Der Knotenpunkt InprocServer32 spezifiziert den Dateipfad und das Threading-Modell der COM-Klasse. Jede COM-Komponente ist durch eine UUID eindeutig identifizierbar. Die ProgID benennt eine Zeichenkette, welche als Äquivalent zur UUID der Komponente gesehen werden kann. Somit ist die ProgID zwar besser lesbar, sie ist jedoch nicht eindeutig. Programmiersprachen wie Visual Basic verwenden ausschließlich die ProgID zur Identifizierung einer Komponente. Die ProgID der Krypto Komponente könnte "KryptoServer.Krypto.1" sein. Der Knotenpunkt TypeLib gibt die UUID der Typenbibliothek wieder. Die versionsunabhängige ProgID wäre in diesem Fall "KryptoServer.Krypto". Sie kann von einem Client verwendet werden, wenn dieser grundsätzlich die neuste Version einer Komponente erstellen möchte.
Komponentenarchitekturen
Die UUIDs für COM-Klassen, deren Schnittstellen und Typbibliotheken können in C++ selbst bestimmt werden. Um eine Eindeutigkeit der UUIDs zu garantieren, empfiehlt Microsoft ein Werkzeug namens „GuidGen“ zu verwenden. In jedem Fall muss der Programmierer die UUID aber selbst erstellen. Möchte er sie ändern, muss er dies ebenfalls von Hand erledigen. Visual Basic erzeugt die UUIDs grundsätzlich automatisch im Hintergrund. Der Programmierer hat keinen direkten Einfluss auf die Vergabe der UUIDs.
DCOM transparent verwenden
Soll eine Komponente entfernt benutzt werden, so kann in der Registrierungsdatenbank ein Eintrag erstellt werden, der auf den entfernten Rechner verweist. Jeder Client, der nun die Komponente verwendet, erzeugt diese - für ihn transparent - auf dem entfernten Rechner. In diesem Fall verwendet der Client die ursprünglich für den lokalen COM-Einsatz entworfene
Interoperabilität von C++ und VB Komponenten
Sollen in einem Projekt COM-Komponenten eingesetzt werden, die in verschiedenen Sprachen entwickelt wurden, so kommt die von Microsoft priorisierte Sprachunabhängigkeit zum tragen. Hier sollen nun die Möglichkeiten untersucht werden, die Komponenten der mittleren Schicht in C++ und in Visual Basic zu entwickeln. Dabei soll das Zusammenspiel unterschiedlicher Server und Clients bewertet werden.
Grundlage einer gemeinsamen Verwendung stellt eine sprachunabhängige Schnittstellenbeschreibung dar. Dies ist für Middlewaretechnologien typischerweise eine IDL-Datei.
Beispielsweise, bietet die CORBA-Implementation von Visigenic einen IDL-Compiler für C++ und Java an. Eine IDL-Datei wird jeweils für C++ und Java übersetzt.
Aus einer sprachunabhängigen Beschreibung entstehen so äquivalente, jedoch sprachabhängige Dateien, welche die Schnittstelle beschreiben. Microsoft legt jedoch nicht eine IDL-Beschreibung zugrunde, sondern verwendet die bereits oben beschriebenen Typbibliotheken. Zwar können aus der IDL-Datei für C/C++ sprachabhängige Dateien kompiliert werden, für alle
Komponentenarchitekturen
anderen Sprachen wird jedoch nur die Typbibliotheksdatei als Grundlage verwendet.
Typbibliotheken (Typelibraries)
Nun soll die Einsatzmöglichkeit von Typbibliotheken auf der Clientseite geprüft werden. Es wird davon ausgegangen, dass eine Komponente zur Verfügung steht, zur der nur die entsprechende Typbibliothek vorhanden ist. Welche Möglichkeiten bestehen, diese Komponente in Visual Basic bzw. C++ einzubinden?
Es soll geprüft werden, wie eine Verwendung über DCOM API möglich ist. Wird die COM API verwendet, ist zu beachten, dass dies nicht die Verwendung von DCOM-Funktionalitäten einschränkt. Die Komponente kann durchaus auf einem entfernten Rechner ausgeführt werden. In diesem Fall wird die bereits oben beschriebene transparente DCOM-Verwendung über Registrierungsdatenbankeinträge durchgeführt.
C/C++ Client
Mit der Einführung von DCOM wurde die COM API um notwendige Funktionen für eine entfernte Verwendung erweitert.
Um eine COM-Komponente lokal zu instanziieren, ruft man die COM API Funktion CoCreateInstance() auf.
CoCreateInstance(<COM-Klassen-ID>, NULL, CLSCTX_INPROC_SERVER | CLSCTX_LOCAL_SERVER, <Schnittstellen-ID>, RueckgabeVariable ); Die für die DCOM-Funktionalität erweiterte Funktion heißt CoCreateInstaceEx(). Sie besitzt zusätzliche Parameter, die den Rechnernamen des Computers entgegennehmen, auf dem die Komponente ausgeführt werden soll.
Komponentenarchitekturen
Aufgrund dessen, dass CoCreateInstanceEx()noch über weitere Parameter verfügt, soll diese nun detailliert werden:
CoCreateInstanceEx( REFCLSID rclsid, //Klassen ID, der zu erstellenden Klasse IUnknown *punkOuter, //Im Falle einer Aggregation die IUnknown //Schnittstelle, des Aggregators DWORD dwClsCtx, //Klassencontext //z.B. CLSCTX_REMOTE_SERVER COSERVERINFO *pServerInfo, //Entfernter Rechnername und //Sicherheitsinformationen ULONG cmq, //Anzahl der Elemente in pResults MULTI_QI *pResults //Array von MULTI_QI Strukturen, s.u. ); Hier die Struktur MULTI_QI:
struct MULTI_QI { const IID * pIID; // Schnittstellen ID des Rückgabewertes IUnknown * pItf; // Rückgabe Variable auf die Schnittstelle HRESULT hr; // Fehlercode };
CoCreateInstanceEx() ist in der Lage, ein entferntes, aber auch lokales, COM-Objekt zu erstellen. In der Struktur COSERVERINFO können hierzu der Rechnername und die zu verwendeten Sicherheitsinformationen übergeben werden. Weiterhin können durch CoCreateInstanceEx() beliebig viele Schnittstellenzeiger in einem Aufruf angefordert werden. Dies bedeutet gerade bei einem entfernten Zugriff eine Netzentlastung.
Damit C++ die Typbibliotheken auslesen kann, hat Microsoft seit der Version 5.0 von Visual C++ den Sprachumfang um die Direktive #import erweitert, um ‚native COM support‘ zu unterstützen [Mic C].
Über die #import Anweisung, erzeugt ein Precompiler die für C++ nötigen Headerfiles direkt aus der Typbibliothek. So kann auch C++ direkt Typbibliotheken verwenden.
Das folgende Beispiel veranschaulicht den Einsatz einer Typbibliothek in C++ durch Pseudocode.
// Globale Anweisung zum Import der Informationen aus der Typbibliothek #import "c:\winnt\system32\krypto.dll"
// Auszug aus dem Quellcode // #import stellt standardmäßig eine Smart-Pointer Unterstützung // der importieren COM-Schnittstellen zur Verfügung IKryptoPtr pKrypto;
Komponentenarchitekturen
// Schnittstelle IKrypto anfordern MULTI_QI qi={&IID_IKrypto,0,NULL};
// Rechnernamen angeben, auf Sicherheitsinformationen verzichten COSERVERINFO si={0,L"FRA098.samsung.de",0,0}; // Instanz entfernt erzeugen
CoCreateInstanceEx(CLSID_Krypto,NULL,CLSCTX_REMOTE_SERVER,&si,1,&qi); // Schnittstellenzeiger aus der Rückgabestruktur in die Smart-Pointer // Klasse übergeben pKrypto = qi.pItf; // Entfernte Methode aufrufen pKrypto->Encrypt_TripeDES(); In Visual Basic ist der Aufruf von CoCreateInstanceEx() durch CreateObject() ersetzt, jedoch werden die Werte des Sicherheitsparameters nicht übergeben. Weiterhin ist es nicht möglich, mehrere Schnittstellenzeiger gleichzeitig anzufordern.
Visual Basic Client
Visual Basic bietet eine unkomplizierte COM-Clienteinbindung. Über ein Menü kann eine Typbibliothek zu einem Projekt hinzugefügt und anschließend benutzt werden.
Visual Basic verwendet automatisch die COM API und eingeschränkt auch die DCOM API. So wird mit dem Aufruf
Dim objKrypto As New KryptoServer.Krypto
in Abhängigkeit der Registrierungsdatenbank ein lokales bzw. entferntes Objekt erstellt. Das heißt, ist in der Registrierungsdatenbank ein Eintrag "RemoteServerName" zu der Komponente enthalten, so wird dieser Rechnername verwendet, um das Objekt auf ihm zu erzeugen. Andernfalls wird ein lokales Objekt erstellt. Wobei mit
Dim objKrypto As KryptoServer.Krypto
Set objKrypto = CreateObject("KryptoServer.Krypto","Entfernter Rechnername") explizit die DCOM-API verwendet wird. So ist es letztlich möglich, den entfernten Rechnernamen, ungeachtet den Registrierungsdatenbankeinträgen, anzugeben.
Komponentenarchitekturen
C/C++ Server
Erstellt man eine Komponente in C/C++, so verwendet diese eine IDL-Beschreibung als Grundlage. Um eine solche IDL-Datei zu erhalten, schreibt man sie entweder von Hand oder lässt sie durch einen Codegenerator erzeugen. Aus dieser werden die für C/C++ benötigten Dateien kompiliert. Weiterhin erzeugt der MIDL-Compiler die Basis für eine separate Proxy-DLL. Auch wird zusätzlich die entsprechende Typbibliothek erzeugt.
Visual Basic Server
Wird ein COM-Server in VB erstellt, so erzeugt Visual Basic keine IDL-Datei. Zur sprachunabhängigen Verwendung steht dann zwar die Typbibliothek zur Verfügung, diese kann aber nicht als Basis für die Erstellung einer separaten Proxy-DLL dienen.
Will man eine solche Proxy-DLL trotzdem erzeugen, sind einige manuell zu erledigende Schritte notwendig: 1.) Extrahieren des IDL-Quellcodes aus der Typbibliothek über das Werkzeug OLEVIEW32. 2.) Dieser IDL-Code muss nun von Hand editiert werden. Hierbei ist keine inhaltliche Änderung notwendig, vielmehr muss die Reihenfolge der Zeilen vertauscht werden. Dieser Schritt wäre bei einer durch Microsoft bewussteren Haltung für die Interoperabilität zwischen C++ und VB, auch über IDL-Dateien, nicht notwendig. 3.) Nun können die Basis Dateien für eine separate Proxy-DLL aus der IDL-Datei erzeugt werden.
Proxy / Stub Code
Wie in Abbildung 2.2 bereits gezeigt, ist für eine entfernte Verwendung einer Komponente ein Proxy-Objekt auf dem Client und ein Stub-Objekt auf dem Server notwendig. Der Text zur Abbildung 2.2 beschrieb, warum Proxy/Stub Objekte notwendig sind. Nun soll die Herkunft solcher Objekte geklärt werden. Da das Stub-Objekt immer im gleichen Prozessadressraum wie das Objekt selbst benötigt wird, kann die COM Laufzeitumgebung diese in jedem Fall zur Verfügung stellen.
Komponentenarchitekturen
Das Proxy-Objekt kann auf zwei Arten zur Verfügung gestellt werden. Entweder erstellt der Komponentenentwickler eine separate Proxy-DLL die auf dem Client Rechner installiert wird oder die komplette Komponente ist auf dem Client vorhanden, so dass der Universal-Marshaller der COM-Laufzeitumgebung dynamisch eine Proxy-DLL erzeugen kann.
In jedem Fall müssen aber die Klassen- und Schnittstellen-IDs in der Registrierungsdatenbank des Clients registriert sein. Eine separate Proxy-DLL bietet den Vorteil, dass alle Arten von Datentypen in der Schnittstelle vorkommen können. Weiterhin können erfahrene Programmierer das Marshalling optimieren.
Übernimmt der Universal-Marshaller die Erzeugung des Proxy-Objektes, so wird die Wahl der Datentypen auf OLE-Automation kompatible Typen eingeschränkt [vgl. Gri99, Seite 16f]. Beispielsweise ist es über den Universal-Marshaller nicht möglich, einen Zeiger auf eine beliebige Klasse als Parameter einer COM-Schnittstelle zu übergeben. Für eine solche Klasse müsste eine komplette COM-Komponente angelegt werden.
Fehlerbehandlungsmechanismen
Zwar ist es prinzipiell jeder Methode einer COM-Schnittstelle freigestellt, welchen Rückgabetyp sie besitzt. Es wird jedoch ein Rückgabewert vom Typ HRESULT empfohlen. Über diesen Rückgabewert kann die Methode ihrerseits selbst Informationen über Ihren Status zurückliefern. Weiterhin kann die COM-Laufzeitumgebung den Aufrufer über eventuell auftretende Fehler informieren. So können gerade bei einer entfernten Verwendung der Komponente Netzwerk-oder Systemfehler auftreten, diese werden ebenfalls von der COM-Laufzeitbibliothek über die HRESULT-Rückgabewerte bekannt gegeben, was auch [Rog97, Seite 104ff] beschreibt.
HRESULTs sind als 32-Bit Integer Wert definiert. Das höchstwertigste Bit legt mit null fest, dass das Ergebnis erfolgreich war. Ist es eine eins, so wird ein Fehler signalisiert. Die nächsten 15 Bits legen die Kategorie fest. Die letzten 16 Bit stellen den eigentlichen Fehlercode dar.
Komponentenarchitekturen

Erfolg/Fehlerbit Kategorie Fehlercode Erfolg/Fehlerbit Kategorie Fehlercode
Abbildung 2.12 - HRESULT Fehlercode
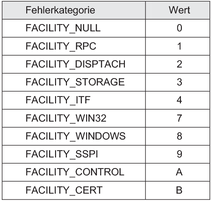
Tabelle 1 - Fehlerkategorien in HRESULT Nach Microsoft Angaben (vgl. auch [Rog97, Seite 106]) sollte für eigene Fehlercodes die Kategorie (FACILITY) FACILITY_ITF verwendet werden. Visual Basic verwendet jedoch generell FACILITY_CONTROL. Hier ein Beispiel für eine COM-Methodendeklaration in C++:
HRESULT Kehrwert(/*[in]*/ double Value,/*[out,retval]*/ double * Result); Visual Basic zeigt diese Methode jedoch anders an:
Function Kehrwert (ByVal Value As Double) As Double Generell stellt VB den Rückgabetyp HRESULT nicht dar. Zwar verwendet VB intern ebenfalls HRESULT, dies wird jedoch dem VB Programmierer verborgen.
Fehlerbehandlung mit Visual Basic
- Arbeit zitieren
- Oliver Klaus Kurt (Autor:in), 2000, Entwicklung eines verteilten Kundeninformationssystems , München, GRIN Verlag, https://www.grin.com/document/185416

Ähnliche Arbeiten



















Kostenlos Autor werden


Kommentare